viernes, 11 de diciembre de 2009
5.1 PRINCIPIOS DE HARDWARE DE ENTRADA Y SALIDA
Distintas personas analizan de varias maneras el hardware de Entrada y Salida. Los ingenieros eléctricos lo hacen en términos de chips, cables, fuentes de poder, etc. Los programadores se fijan en la interfaz que se presenta al software (los comandos que aceptan el hardware, las funciones que realiza y los errores que puede informar.
En este trabajo nos interesaremos por la programación de los dispositivos de entrada y salida no por su diseño, construcción o mantenimiento, así nuestro interés estará restringido a la forma de programar el hardware y no su funcionamiento interno. Sin embargo es frecuente que la programación de muchos dispositivos de entrada y salida este íntimamente ligada con su operación interna.

Distintas personas analizan de varias maneras el hardware de Entrada y Salida. Los ingenieros eléctricos lo hacen en términos de chips, cables, fuentes de poder, etc. Los programadores se fijan en la interfaz que se presenta al software (los comandos que aceptan el hardware, las funciones que realiza y los errores que puede informar.
En este trabajo nos interesaremos por la programación de los dispositivos de entrada y salida no por su diseño, construcción o mantenimiento, así nuestro interés estará restringido a la forma de programar el hardware y no su funcionamiento interno. Sin embargo es frecuente que la programación de muchos dispositivos de entrada y salida este íntimamente ligada con su operación interna.

5.1.1 DISPOSITIVOS DE ENTRADA Y SALIDA.
Los dispositivos de entrada y saluda se pueden dividir de manera general en dos categorías: dispositivos de bloque y dispositivos de carácter.
Dispositivo de Bloque: Es aquel que almacena la información en bloques de tamaño fijo, cada uno con su propia dirección. Los tamaños comunes de los bloques van desde 128 bytes hasta 1024 bytes. La propiedad esencial de un dispositivo de bloque es la posibilidad de leer o escribir en un bloque de forma independiente de los demás, es decir, el programa puede leer o escribir en cualquiera de los bloques.
Entre los dispositivos de bloque se pueden encontrar:
•CD - ROM: Acrónimo de Compact Disc-Read Only Memory. Estándar de almacenamiento de archivos informáticos en disco compacto. Se caracteriza por ser de sólo lectura. Otros estándares son el CD-R o WORM (permite grabar la información una sola vez), el CD-DA (permite reproducir sonido), el CD-I (define una plataforma multimedia) y el PhotoCD (permite visualizar imágenes estáticas).
•Disco Duro: Los discos duros proporcionan un acceso más rápido a los datos que los discos flexibles y pueden almacenar mucha más información. Al ser las láminas rígidas, pueden superponerse unas sobre otras, de modo que una unidad de disco duro puede tener acceso a más de una de ellas. La mayoría de los discos duros tienen de dos a ocho láminas. Un disco duro normal gira a una velocidad de 3.600 revoluciones por minuto y las cabezas de lectura y escritura se mueven en la superficie del disco sobre una burbuja de aire de una profundidad de 10 a 25 millonésimas de pulgada. El disco duro va sellado para evitar la interferencia de partículas en la mínima distancia que existe entre las cabezas y el disco.
•Disquete o Disco flexible: Es un elemento plano de mylar recubierto con óxido de hierro que contiene partículas minúsculas capaces de mantener un campo magnético, y encapsulado en una carcasa o funda protectora de plástico. La información se almacena en el disquete mediante la cabeza de lectura y escritura de la unidad de disco, que altera la orientación magnética de las partículas. La orientación en una dirección representa el valor binario 1, y la orientación en otra el valor binario 0
.Dependiendo de su capacidad, un disco de este tipo puede contener desde algunos cientos de miles de bytes de información hasta casi tres millones (2,88 Mb). Un disco de 3y pulgada encerrada en plástico rígido se denomina normalmente disquete pero puede llamarse también disco flexible.
•Dispositivo de Carácter: Es aquel que envía o recibe un flujo de caracteres, sin sujetarse a una estructura de bloques. No se pueden utilizar direcciones ni tienen una operación de búsqueda.
Entre los dispositivos de carácter se pueden mencionar:
•Mouse: Es el segundo dispositivo de entrada más utilizado. El mouse o ratón es arrastrado a lo largo de una superficie para maniobrar un apuntador en la pantalla del monitor. Fue inventado por Douglas Engelbart y su nombre se deriva por su forma la cual se asemeja a la de un ratón.
•Monitores: El monitor ó pantalla de vídeo, es el dispositivo de salida más común. Hay algunos que forman parte del cuerpo de la computadora y otros están separados de la misma. Existen muchas formas de clasificar los monitores, la básica es en término de sus capacidades de color, pueden ser: Monocromáticos, despliegan sólo 2 colores, uno para el fondo y otro para la superficie. Los colores pueden ser blanco y negro, verde y negro ó ámbar y negro. Escala de Grises, un monitor a escala de grises es un tipo especial de monitor monocromático capaz de desplegar diferentes tonos de grises. Color: Los monitores de color pueden desplegar de 4 hasta 1 millón de colores diferentes.
•Impresoras de Línea: de línea: Son rápidas y ruidosas. Tienen la desventaja de estar limitadas a la impresión de caracteres, por lo que no son apropiadas para aplicaciones donde los gráficos son un ingrediente esencial del producto acabado. imprimen una línea de puntos a la vez. Se alinean martillos similares a agujas sobre el ancho del papel.
•Tarjetas Perforadas: Habían, sido inventada en los años de la revolución industrial (finales del siglo XVIII) por el francés Jacquard y perfeccionado por el estadounidense Hermand Hollerith en 1890. Se usaron para acumular y procesar automáticamente gran cantidad de datos. Durante décadas, desde mediados de los cincuentas la tecnología de las tarjetas perforadas se perfeccionó con la implantación de más dispositivos con capacidades más complejas. Dado que cada tarjeta contenía en general un registro (Un nombre, dirección, etc.) el procesamiento de la tarjeta perforada se conoció también como procesamiento de registro unitario.

Los dispositivos de entrada y saluda se pueden dividir de manera general en dos categorías: dispositivos de bloque y dispositivos de carácter.
Dispositivo de Bloque: Es aquel que almacena la información en bloques de tamaño fijo, cada uno con su propia dirección. Los tamaños comunes de los bloques van desde 128 bytes hasta 1024 bytes. La propiedad esencial de un dispositivo de bloque es la posibilidad de leer o escribir en un bloque de forma independiente de los demás, es decir, el programa puede leer o escribir en cualquiera de los bloques.
Entre los dispositivos de bloque se pueden encontrar:
•CD - ROM: Acrónimo de Compact Disc-Read Only Memory. Estándar de almacenamiento de archivos informáticos en disco compacto. Se caracteriza por ser de sólo lectura. Otros estándares son el CD-R o WORM (permite grabar la información una sola vez), el CD-DA (permite reproducir sonido), el CD-I (define una plataforma multimedia) y el PhotoCD (permite visualizar imágenes estáticas).
•Disco Duro: Los discos duros proporcionan un acceso más rápido a los datos que los discos flexibles y pueden almacenar mucha más información. Al ser las láminas rígidas, pueden superponerse unas sobre otras, de modo que una unidad de disco duro puede tener acceso a más de una de ellas. La mayoría de los discos duros tienen de dos a ocho láminas. Un disco duro normal gira a una velocidad de 3.600 revoluciones por minuto y las cabezas de lectura y escritura se mueven en la superficie del disco sobre una burbuja de aire de una profundidad de 10 a 25 millonésimas de pulgada. El disco duro va sellado para evitar la interferencia de partículas en la mínima distancia que existe entre las cabezas y el disco.
•Disquete o Disco flexible: Es un elemento plano de mylar recubierto con óxido de hierro que contiene partículas minúsculas capaces de mantener un campo magnético, y encapsulado en una carcasa o funda protectora de plástico. La información se almacena en el disquete mediante la cabeza de lectura y escritura de la unidad de disco, que altera la orientación magnética de las partículas. La orientación en una dirección representa el valor binario 1, y la orientación en otra el valor binario 0
.Dependiendo de su capacidad, un disco de este tipo puede contener desde algunos cientos de miles de bytes de información hasta casi tres millones (2,88 Mb). Un disco de 3y pulgada encerrada en plástico rígido se denomina normalmente disquete pero puede llamarse también disco flexible.
•Dispositivo de Carácter: Es aquel que envía o recibe un flujo de caracteres, sin sujetarse a una estructura de bloques. No se pueden utilizar direcciones ni tienen una operación de búsqueda.
Entre los dispositivos de carácter se pueden mencionar:
•Mouse: Es el segundo dispositivo de entrada más utilizado. El mouse o ratón es arrastrado a lo largo de una superficie para maniobrar un apuntador en la pantalla del monitor. Fue inventado por Douglas Engelbart y su nombre se deriva por su forma la cual se asemeja a la de un ratón.
•Monitores: El monitor ó pantalla de vídeo, es el dispositivo de salida más común. Hay algunos que forman parte del cuerpo de la computadora y otros están separados de la misma. Existen muchas formas de clasificar los monitores, la básica es en término de sus capacidades de color, pueden ser: Monocromáticos, despliegan sólo 2 colores, uno para el fondo y otro para la superficie. Los colores pueden ser blanco y negro, verde y negro ó ámbar y negro. Escala de Grises, un monitor a escala de grises es un tipo especial de monitor monocromático capaz de desplegar diferentes tonos de grises. Color: Los monitores de color pueden desplegar de 4 hasta 1 millón de colores diferentes.
•Impresoras de Línea: de línea: Son rápidas y ruidosas. Tienen la desventaja de estar limitadas a la impresión de caracteres, por lo que no son apropiadas para aplicaciones donde los gráficos son un ingrediente esencial del producto acabado. imprimen una línea de puntos a la vez. Se alinean martillos similares a agujas sobre el ancho del papel.
•Tarjetas Perforadas: Habían, sido inventada en los años de la revolución industrial (finales del siglo XVIII) por el francés Jacquard y perfeccionado por el estadounidense Hermand Hollerith en 1890. Se usaron para acumular y procesar automáticamente gran cantidad de datos. Durante décadas, desde mediados de los cincuentas la tecnología de las tarjetas perforadas se perfeccionó con la implantación de más dispositivos con capacidades más complejas. Dado que cada tarjeta contenía en general un registro (Un nombre, dirección, etc.) el procesamiento de la tarjeta perforada se conoció también como procesamiento de registro unitario.

5.1.2 CONTROLADORES DE DISPOSITIVOS
Las unidades de entrada y salida constan por lo general de un componente mecánico y otro electrónico. El componente electrónico se llama controlador de dispositivo de adaptador.
La tarjeta controladora tiene por lo general un conector, en el que se puede conectar el cable que va al dispositivo en sí. Muchos controladores pueden manejar dos, cuatro y hasta ocho dispositivos idénticos. Si la interfaz entre el controlador y el dispositivo es estándar, ya sea un estándar oficial, de tipo ANSI, IEEE o ISO, o bien un estándar de hecho, entonces las compañías pueden fabricar controladores o dispositivos que se ajusten a esa interfaz.
Mencionamos esa distinción entre controlado y dispositivo por que el sistema operativo casi siempre trabaja con el controlador y no con el dispositivo. Casi todas las micro y mini computadoras utilizan el modelo de un bus para la comunicación entre la CPU y los controladores. Los grandes mainframes utilizan con frecuencia otro modelo, con varios buses y computadoras especializadas en Entrada y Salida llamadas canales de entrada y salida que toman cierta carga de entrada y salida fuera de la CPU principal.
La labor del controlador es convertir el flujo de bits en serie en un bloque de bytes y llevar a cabo cualquier corrección de errores necesaria. Lo común es que el bloque de bytes ensamble, bit a bit, en un buffer dentro del controlador. Después a verificar la suma y declarar al bloque libre de errores, se le puede copiar en la memoria principal.
El controlador de una terminal CRT también funciona como un dispositivo de bits en un nivel igual de bajo. Lee bytes que contienen caracteres a exhibir en la memoria y genera las señales utilizadas para modular la luz CRT para que esta se escriba en la pantalla. El controlador también genera las señales para que la luz CRT vuelva a realizar un trazo horizontal después de terminar una línea de rastreo, así como las señales para que se vuelva a hacer un trazo vertical después de rastrear en toda la pantalla. De no ser por el controlador CRT, el programador del sistema operativo tendría que programar en forma explícita el rastreo análogo del tubo de rayos catódicos. Con el controlador, el sistema operativo inicializa éste con pocos parámetros, tales como el número de caracteres por línea y el número de líneas en la pantalla, para dejar que el controlador se encargue de dirigir en realidad el rayo de luz.
Cada controlador tiene unos cuantos registros que se utiliza para la comunicación con la CPU. En ciertas computadoras, estos registros son parte del espacio normal de direcciones de la memoria.
El sistema operativo realiza la entrada y salida al escribir comandos en los registros de los controladores. Muchos de los comandos tienen parámetros, los cuales también se cargan de los registros del controlador. Al aceptar un comando, la CPU puede dejar al controlador y dedicarse a otro trabajo. Al terminar el comando, el controlador provoca la interrupción para permitir que el sistema operativo obtenga el control de la CPU y verifique los resultados de la operación. La CPU obtiene los resultados y el estado del dispositivo al leer uno o más bytes de información de los registros del controlador.

Las unidades de entrada y salida constan por lo general de un componente mecánico y otro electrónico. El componente electrónico se llama controlador de dispositivo de adaptador.
La tarjeta controladora tiene por lo general un conector, en el que se puede conectar el cable que va al dispositivo en sí. Muchos controladores pueden manejar dos, cuatro y hasta ocho dispositivos idénticos. Si la interfaz entre el controlador y el dispositivo es estándar, ya sea un estándar oficial, de tipo ANSI, IEEE o ISO, o bien un estándar de hecho, entonces las compañías pueden fabricar controladores o dispositivos que se ajusten a esa interfaz.
Mencionamos esa distinción entre controlado y dispositivo por que el sistema operativo casi siempre trabaja con el controlador y no con el dispositivo. Casi todas las micro y mini computadoras utilizan el modelo de un bus para la comunicación entre la CPU y los controladores. Los grandes mainframes utilizan con frecuencia otro modelo, con varios buses y computadoras especializadas en Entrada y Salida llamadas canales de entrada y salida que toman cierta carga de entrada y salida fuera de la CPU principal.
La labor del controlador es convertir el flujo de bits en serie en un bloque de bytes y llevar a cabo cualquier corrección de errores necesaria. Lo común es que el bloque de bytes ensamble, bit a bit, en un buffer dentro del controlador. Después a verificar la suma y declarar al bloque libre de errores, se le puede copiar en la memoria principal.
El controlador de una terminal CRT también funciona como un dispositivo de bits en un nivel igual de bajo. Lee bytes que contienen caracteres a exhibir en la memoria y genera las señales utilizadas para modular la luz CRT para que esta se escriba en la pantalla. El controlador también genera las señales para que la luz CRT vuelva a realizar un trazo horizontal después de terminar una línea de rastreo, así como las señales para que se vuelva a hacer un trazo vertical después de rastrear en toda la pantalla. De no ser por el controlador CRT, el programador del sistema operativo tendría que programar en forma explícita el rastreo análogo del tubo de rayos catódicos. Con el controlador, el sistema operativo inicializa éste con pocos parámetros, tales como el número de caracteres por línea y el número de líneas en la pantalla, para dejar que el controlador se encargue de dirigir en realidad el rayo de luz.
Cada controlador tiene unos cuantos registros que se utiliza para la comunicación con la CPU. En ciertas computadoras, estos registros son parte del espacio normal de direcciones de la memoria.
El sistema operativo realiza la entrada y salida al escribir comandos en los registros de los controladores. Muchos de los comandos tienen parámetros, los cuales también se cargan de los registros del controlador. Al aceptar un comando, la CPU puede dejar al controlador y dedicarse a otro trabajo. Al terminar el comando, el controlador provoca la interrupción para permitir que el sistema operativo obtenga el control de la CPU y verifique los resultados de la operación. La CPU obtiene los resultados y el estado del dispositivo al leer uno o más bytes de información de los registros del controlador.

5.2 PRINCIPIOS DE SOFTWARE DE ENTRADA Y SALIDA
Los principios de software en la entrada - salida se resumen en cuatro puntos: el software debe ofrecer manejadores de interrupciones, manejadores de dispositivos, software que sea independiente de los dispositivos y software para usuarios.
Manejadores de Interrupciones.
El primer objetivo referente a los manejadores de interrupciones consiste en que el programador o el usuario no debe darse cuenta de los manejos de bajo nivel para los casos en que el dispositivo está ocupado y se debe suspender el proceso o sincronizar algunas tareas. Desde el punto de vista del proceso o usuario, el sistema simplemente se tardó más o menos en responder a su petición.
Manejadores de Dispositivos.
El sistema debe proveer los manejadores de dispositivos necesarios para los periféricos, así como ocultar las peculiaridades del manejo interno de cada uno de ellos, tales como el formato de la información, los medios mecánicos, los niveles de voltaje y otros. Por ejemplo, si el sistema tiene varios tipos diferentes de discos duros, para el usuario o programador las diferencias técnicas entre ellos no le deben importar, y los manejadores le deben ofrecer el mismo conjunto de rutinas para leer y escribir datos.
Software que sea independiente de los dispositivos.
Este es un nivel superior de independencia que el ofrecido por los manejadores de dispositivos. Aquí el sistema operativo debe ser capaz, en lo más posible, de ofrecer un conjunto de utilerías para accesar periféricos o programarlos de una manera consistente. Por ejemplo, que para todos los dispositivos orientados a bloques se tenga una llamada para decidir si se desea usar 'buffers' o no, o para posicionarse en ellos.
Software para Usuarios.
La mayoría de las rutinas de entrada - salida trabajan en modo privilegiado, o son llamadas al sistema que se ligan a los programas del usuario formando parte de sus aplicaciones y que no le dejan ninguna flexibilidad al usuario en cuanto a la apariencia de los datos. Existen otras librerías en donde el usuario si tiene poder de decisión (por ejemplo la llamada a "printf" en el lenguaje"C"). Otra facilidad ofrecida son las áreas de trabajos encolados (spooling areas), tales como las de impresión y correo electrónico.

Los principios de software en la entrada - salida se resumen en cuatro puntos: el software debe ofrecer manejadores de interrupciones, manejadores de dispositivos, software que sea independiente de los dispositivos y software para usuarios.
Manejadores de Interrupciones.
El primer objetivo referente a los manejadores de interrupciones consiste en que el programador o el usuario no debe darse cuenta de los manejos de bajo nivel para los casos en que el dispositivo está ocupado y se debe suspender el proceso o sincronizar algunas tareas. Desde el punto de vista del proceso o usuario, el sistema simplemente se tardó más o menos en responder a su petición.
Manejadores de Dispositivos.
El sistema debe proveer los manejadores de dispositivos necesarios para los periféricos, así como ocultar las peculiaridades del manejo interno de cada uno de ellos, tales como el formato de la información, los medios mecánicos, los niveles de voltaje y otros. Por ejemplo, si el sistema tiene varios tipos diferentes de discos duros, para el usuario o programador las diferencias técnicas entre ellos no le deben importar, y los manejadores le deben ofrecer el mismo conjunto de rutinas para leer y escribir datos.
Software que sea independiente de los dispositivos.
Este es un nivel superior de independencia que el ofrecido por los manejadores de dispositivos. Aquí el sistema operativo debe ser capaz, en lo más posible, de ofrecer un conjunto de utilerías para accesar periféricos o programarlos de una manera consistente. Por ejemplo, que para todos los dispositivos orientados a bloques se tenga una llamada para decidir si se desea usar 'buffers' o no, o para posicionarse en ellos.
Software para Usuarios.
La mayoría de las rutinas de entrada - salida trabajan en modo privilegiado, o son llamadas al sistema que se ligan a los programas del usuario formando parte de sus aplicaciones y que no le dejan ninguna flexibilidad al usuario en cuanto a la apariencia de los datos. Existen otras librerías en donde el usuario si tiene poder de decisión (por ejemplo la llamada a "printf" en el lenguaje"C"). Otra facilidad ofrecida son las áreas de trabajos encolados (spooling areas), tales como las de impresión y correo electrónico.

5.2.1 OBJETIVOS DE SOFTWARE DE ENTRADA Y SALIDA
Un concepto clave es la independencia del dispositivo:
•Debe ser posible escribir programas que se puedan utilizar con archivos en distintos dispositivos, sin tener que modificar los programas para cada tipo de dispositivo.
•El problema debe ser resuelto por el S. O.
El objetivo de lograr nombres uniformes está muy relacionado con el de independencia del dispositivo.Todos los archivos y dispositivos adquieren direcciones de la misma forma, es decir mediante el nombre de su ruta de acceso.Otro aspecto importante del software es el manejo de errores de e / s:
•Generalmente los errores deben manejarse lo más cerca posible del hardware.
•Solo si los niveles inferiores no pueden resolver el problema, se informa a los niveles superiores.
•Generalmente la recuperación se puede hacer en un nivel inferior y de forma transparente.
Otro aspecto clave son las transferencias síncronas (por bloques) o asíncronas (controlada por interruptores):
•La mayoría de la e / s es asíncrona: la CPU inicia la transferencia y realiza otras tareas hasta una interrupción.
•La programación es más fácil si la e / s es síncrona (por bloques): el programa se suspende automáticamente hasta que los datos estén disponibles en el buffer.
El S. O. se encarga de hacer que operaciones controladas por interruptores parezcan del tipo de bloques para el usuario.
También el S. O. debe administrar los dispositivos compartidos (ej.: discos) y los de uso exclusivo (ej.: impresoras).
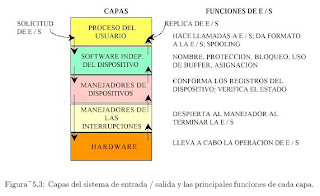
Generalmente el software de e / s se estructura en capas
•Manejadores de interrupciones.
•Directivas de dispositivos.
•Software de S. O. independiente de los dispositivos.
•Software a nivel usuario.
Un concepto clave es la independencia del dispositivo:
•Debe ser posible escribir programas que se puedan utilizar con archivos en distintos dispositivos, sin tener que modificar los programas para cada tipo de dispositivo.
•El problema debe ser resuelto por el S. O.
El objetivo de lograr nombres uniformes está muy relacionado con el de independencia del dispositivo.Todos los archivos y dispositivos adquieren direcciones de la misma forma, es decir mediante el nombre de su ruta de acceso.Otro aspecto importante del software es el manejo de errores de e / s:
•Generalmente los errores deben manejarse lo más cerca posible del hardware.
•Solo si los niveles inferiores no pueden resolver el problema, se informa a los niveles superiores.
•Generalmente la recuperación se puede hacer en un nivel inferior y de forma transparente.
Otro aspecto clave son las transferencias síncronas (por bloques) o asíncronas (controlada por interruptores):
•La mayoría de la e / s es asíncrona: la CPU inicia la transferencia y realiza otras tareas hasta una interrupción.
•La programación es más fácil si la e / s es síncrona (por bloques): el programa se suspende automáticamente hasta que los datos estén disponibles en el buffer.
El S. O. se encarga de hacer que operaciones controladas por interruptores parezcan del tipo de bloques para el usuario.
También el S. O. debe administrar los dispositivos compartidos (ej.: discos) y los de uso exclusivo (ej.: impresoras).
Generalmente el software de e / s se estructura en capas
•Manejadores de interrupciones.
•Directivas de dispositivos.
•Software de S. O. independiente de los dispositivos.
•Software a nivel usuario.

5.2.3 MANEJADORES DE DISPOSITIVOS
Todo el código que depende de los dispositivos aparece en los manejadores de dispositivos.
Cada controlador posee uno o más registros de dispositivos:
•Se utilizan para darle los comandos.
•Los manejadores de dispositivos proveen estos comandos y verifican su ejecución adecuada.
La labor de un manejador de dispositivos es la de:
•Aceptar las solicitudes abstractas que le hace el software independiente del dispositivo.
•Verificar la ejecución de dichas solicitudes.
Si al recibir una solicitud el manejador está ocupado con otra solicitud, agregara la nueva solicitud a una cola de solicitudes pendientes.
La solicitud de e / s, por ej. Para un disco, se debe traducir de términos abstractos a términos concretos:
•El manejador de disco debe:
oEstimar el lugar donde se encuentra en realidad el bloque solicitado.
oVerificar si el motor de la unidad funciona.
oVerificar si el brazo está colocado en el cilindro adecuado, etc.
oResumiendo: debe decidir cuáles son las operaciones necesarias del
controlador y su orden.
oEnvía los comandos al controlador al escribir en los registros de dispositivo
del mismo.
oFrecuentemente el manejador del dispositivo se bloquea hasta que el
controlador realiza cierto trabajo; una interrupción lo libera de este
bloqueo.
oAl finalizar la operación debe verificar los errores.
oSi todo esta o.k. transferirá los datos al software independiente del
dispositivo.
oRegresa información de estado sobre los errores a quien lo llamó.
oInicia otra solicitud pendiente o queda en espera.

Todo el código que depende de los dispositivos aparece en los manejadores de dispositivos.
Cada controlador posee uno o más registros de dispositivos:
•Se utilizan para darle los comandos.
•Los manejadores de dispositivos proveen estos comandos y verifican su ejecución adecuada.
La labor de un manejador de dispositivos es la de:
•Aceptar las solicitudes abstractas que le hace el software independiente del dispositivo.
•Verificar la ejecución de dichas solicitudes.
Si al recibir una solicitud el manejador está ocupado con otra solicitud, agregara la nueva solicitud a una cola de solicitudes pendientes.
La solicitud de e / s, por ej. Para un disco, se debe traducir de términos abstractos a términos concretos:
•El manejador de disco debe:
oEstimar el lugar donde se encuentra en realidad el bloque solicitado.
oVerificar si el motor de la unidad funciona.
oVerificar si el brazo está colocado en el cilindro adecuado, etc.
oResumiendo: debe decidir cuáles son las operaciones necesarias del
controlador y su orden.
oEnvía los comandos al controlador al escribir en los registros de dispositivo
del mismo.
oFrecuentemente el manejador del dispositivo se bloquea hasta que el
controlador realiza cierto trabajo; una interrupción lo libera de este
bloqueo.
oAl finalizar la operación debe verificar los errores.
oSi todo esta o.k. transferirá los datos al software independiente del
dispositivo.
oRegresa información de estado sobre los errores a quien lo llamó.
oInicia otra solicitud pendiente o queda en espera.

5.2.4 SOFTWARE DE ENTRADA Y SALIDA INDEPENDIENTE DE DISPOSITIVOS
Funciones generalmente realizadas por el software independiente del dispositivo:
•Interfaz uniforme para los manejadores de dispositivos.
•Nombres de los dispositivos.
•Protección del dispositivo.
•Proporcionar un tamaño de bloque independiente del dispositivo.
•Uso de buffers.
•Asignación de espacio en los dispositivos por bloques.
•Asignación y liberación de los dispositivos de uso exclusivo.
•Informe de errores.
Las funciones básicas del software independiente del dispositivo son:
•Efectuar las funciones de e / s comunes a todos los dispositivos.
•Proporcionar una interfaz uniforme del software a nivel usuario.
El software independiente del dispositivo asocia los nombres simbólicos de los dispositivos con el nombre adecuado.
Un nombre de dispositivo determina de manera única el nodo-i de un archivo especial:
•Este nodo-i contiene el número principal del dispositivo, que se utiliza para localizar el manejador apropiado.
•El nodo-i contiene también el número secundario de dispositivo, que se transfiere como parámetro al manejador para determinar la unidad por leer o escribir.
El software independiente del dispositivo debe:
•Ocultar a los niveles superiores los diferentes tamaños de sector de los distintos discos.
•Proporcionar un tamaño uniforme de los bloques, por ej.: considerar varios sectores físicos como un solo bloque lógico.

Funciones generalmente realizadas por el software independiente del dispositivo:
•Interfaz uniforme para los manejadores de dispositivos.
•Nombres de los dispositivos.
•Protección del dispositivo.
•Proporcionar un tamaño de bloque independiente del dispositivo.
•Uso de buffers.
•Asignación de espacio en los dispositivos por bloques.
•Asignación y liberación de los dispositivos de uso exclusivo.
•Informe de errores.
Las funciones básicas del software independiente del dispositivo son:
•Efectuar las funciones de e / s comunes a todos los dispositivos.
•Proporcionar una interfaz uniforme del software a nivel usuario.
El software independiente del dispositivo asocia los nombres simbólicos de los dispositivos con el nombre adecuado.
Un nombre de dispositivo determina de manera única el nodo-i de un archivo especial:
•Este nodo-i contiene el número principal del dispositivo, que se utiliza para localizar el manejador apropiado.
•El nodo-i contiene también el número secundario de dispositivo, que se transfiere como parámetro al manejador para determinar la unidad por leer o escribir.
El software independiente del dispositivo debe:
•Ocultar a los niveles superiores los diferentes tamaños de sector de los distintos discos.
•Proporcionar un tamaño uniforme de los bloques, por ej.: considerar varios sectores físicos como un solo bloque lógico.

5.2.5 ESPACIO DEL USUARIO PARA SOFTWARE DE ENTRADA Y SALIDA
La mayoría del software de e / s está dentro del S. O.
Una pequeña parte consta de bibliotecas ligadas entre sí con los programas del usuario.
La biblioteca estándar de e / s contiene varios procedimientos relacionados con e / s y todos se ejecutan como parte de los programas del usuario.
Otra categoría importante de software de e / s a nivel usuario es el sistema de spooling.
El spooling es una forma de trabajar con los dispositivos de e /s de uso exclusivo en un sistema de multiprogramación:
•El ejemplo típico lo constituye la impresora de líneas.
•Los procesos de usuario no abren el archivo correspondiente a la impresora.
•Se crea un proceso especial, llamado demonio en algunos sistemas.
•Se crea un directorio de spooling.
Para imprimir un archivo:
•Un proceso genera todo el archivo por imprimir y lo coloca en el directorio de spooling.
•El proceso especial, único con permiso para utilizar el archivo especial de la impresora, debe imprimir los archivos en el directorio.
•Se evita el posible problema de tener un proceso de usuario que mantenga un recurso tomado largo tiempo.
Un esquema similar también es aplicable para la transferencia de archivos entre equipos conectados:
•Un usuario coloca un archivo en un directorio de spooling de la red.
•Posteriormente, el proceso especial lo toma y transmite. Un ej. son los sistemas de correo electrónico.

La mayoría del software de e / s está dentro del S. O.
Una pequeña parte consta de bibliotecas ligadas entre sí con los programas del usuario.
La biblioteca estándar de e / s contiene varios procedimientos relacionados con e / s y todos se ejecutan como parte de los programas del usuario.
Otra categoría importante de software de e / s a nivel usuario es el sistema de spooling.
El spooling es una forma de trabajar con los dispositivos de e /s de uso exclusivo en un sistema de multiprogramación:
•El ejemplo típico lo constituye la impresora de líneas.
•Los procesos de usuario no abren el archivo correspondiente a la impresora.
•Se crea un proceso especial, llamado demonio en algunos sistemas.
•Se crea un directorio de spooling.
Para imprimir un archivo:
•Un proceso genera todo el archivo por imprimir y lo coloca en el directorio de spooling.
•El proceso especial, único con permiso para utilizar el archivo especial de la impresora, debe imprimir los archivos en el directorio.
•Se evita el posible problema de tener un proceso de usuario que mantenga un recurso tomado largo tiempo.
Un esquema similar también es aplicable para la transferencia de archivos entre equipos conectados:
•Un usuario coloca un archivo en un directorio de spooling de la red.
•Posteriormente, el proceso especial lo toma y transmite. Un ej. son los sistemas de correo electrónico.

5.3 DISCOS RAM
Un disco RAM o unidad RAM es una unidad de disco que usa una zona de memoria RAM del sistema como almacenamiento secundario en lugar de un medio magnético (como los discos duros y las disqueteras) o memoria flash, implementada como un controlador de dispositivo más. El tiempo de acceso mejora drásticamente, debido a que la memoria RAM es varios órdenes de magnitud más rápida que las unidades de disco reales. Sin embargo, la volatilidad de la memoria RAM implica que los datos almacenados en un disco RAM se perderán si falla la alimentación (por ejemplo, cuando el ordenador se apaga). Los discos RAM suelen usarse para almacenar datos temporales o para guardar programas descomprimidos durante cortos periodos.
Los discos RAM fueron populares como unidades de arranque en los años 1980, cuando los discos duros eran caros y las disqueteras demasiado lentas, por lo que unos pocos sistemas, como el Amiga y el Apple IIgs, soportaban arrancar desde un disco RAM. A cambio de dedicar un poco de memoria principal, el sistema podía realizar un reinicio en caliente y volver al sistema operativo en pocos segundos en lugar de minutos. Algunos sistemas contaban con discos RAM alimentados por baterías, de forma que sus contenidos no se perdían cuando el sistema se apagaba.
La adecuada implementación de un caché de disco suele obviar las motivaciones relacionadas con el rendimiento que impulsan a usar un disco RAM, adoptando un papel parecido (acceso rápido a los datos que en realidad residen en un disco) sin sus varias desventajas (pérdida de datos en caso de apagado, particionado estático, etcétera). Los discos RAM son, sin embargo, indispensables en situaciones en las que un disco físico no está disponible o en las que el acceso o cambios a éste no es deseable (como en el caso de un LiveCD. También pueden usarse en dispositivos de tipo quiosco, en los que los cambios hechos al sistema no se guardan en el disco físico y la configuración original del sistema se carga de éste cada vez que el sistema es reiniciado.
Un disco duro (del inglés hard disk (HD)) es un disco magnético en el que puedes almacenar datos de ordenador. El disco duro es la parte de tu ordenador que contiene la información electrónica y donde se almacenan todos los programas (software). Es uno de los componentes del hardware más importantes dentro de tu PC.
El término duro se utiliza para diferenciarlo del disco flexible o disquete (floppy en inglés). Los discos duros pueden almacenar muchos más datos y son más rápidos que los disquetes. Por ejemplo, un disco duro puede llegar a almacenar más de 100 gigabytes, mientras que la mayoría de los disquetes tienen una memoria máxima de 1.4 megabytes.
Componentes de un disco duro:
Normalmente un disco duro consiste en varios discos o platos. Cada disco requiere dos cabezales de lectura/grabación, uno para cada lado. Todos los cabezales de lectura/grabación están unidos a un solo brazo de acceso, de modo que no puedan moverse independientemente. Cada disco tiene el mismo número de pistas, y a la parte de la pista que corta a través de todos los discos se le llama cilindro.
Características de un disco duro:
Las características que se deben tener en cuenta en un disco duro son:
•Tiempo medio de acceso: Tiempo medio que tarda la aguja en situarse en la pista y el sector deseado; es la suma del Tiempo medio de búsqueda (situarse en la pista), tiempo de lectura/escritura y la Latencia media (situarse en el sector).
•Tiempo medio de búsqueda: Tiempo medio que tarda la aguja en situarse en la pista deseada; es la mitad del tiempo empleado por la aguja en ir desde la pista más periférica hasta la más central del disco.
•Tiempo de lectura/escritura: Tiempo medio que tarda el disco en leer o escribir nueva información, el tiempo depende de la cantidad de información que se quiere leer o escribir, el tamaño de bloque, el numero de cabezales, el tiempo por vuelta y la cantidad de sectores por pista.
•Latencia media: Tiempo medio que tarda la aguja en situarse en el sector deseado; es la mitad del tiempo empleado en una rotación completa del disco.
•Velocidad de rotación: Revoluciones por minuto de los platos. A mayor velocidad de rotación, menor latencia media.
•Tasa de transferencia: Velocidad a la que puede transferir la información a la computadora una vez la aguja está situada en la pista y sector correctos. Puede ser velocidad sostenida o de pico.
Otras características son:
•Caché de pista: Es una memoria tipo RAM dentro del disco duro. Los discos duros de estado sólido utilizan cierto tipo de memorias construidas con semiconductores para almacenar la información. El uso de esta clase de discos generalmente se limita a
las supercomputadoras, por su elevado precio.
•Interfaz: Medio de comunicación entre el disco duro y la computadora. Puede ser IDE/ATA, SCSI, SATA, USB, Firewire, SAS
•Landz: Zona sobre las que aterrizan las cabezas una vez apagada la computadora.
Actualmente la nueva generación de discos duros utiliza la tecnología de grabación perpendicular (PMR), la cual permite mayor densidad de almacenamiento. También existen discos llamados "Ecológicos" (GP - Green Power), los cuales hacen un uso más eficiente de la energía. Se está empezando a observar que la Unidad de estado sólido es posible que termine sustituyendo al disco duro a largo plazo. También hay que añadir los nuevos discos duros basados en el tipo de memorias Flash, que algunas empresas, como ASUS, incorporó recientemente en sus modelos. Los mismos arrancan en 4GB a 512 GB.1...
Son muy rápidos ya que no tienen partes móviles y consumen menos energía. Todo esto les hace muy fiables y casi indestructibles. Un nuevo formato de discos duros basados en tarjetas de memorias. Sin embargo su costo por GB es aún muy elevado ya que el coste de un HD de 160 GB es equivalente a un SSD de 8 GB.
Los recursos tecnológicos y el saber hacer requeridos para el desarrollo y la producción de discos modernos implica que desde 2007, más del 98% de los discos duros del mundo son fabricados por un conjunto de grandes empresas: Seagate (que ahora es propietaria de Maxtor), Western Digital, Samsung e Hitachi (que es propietaria de la antigua división de fabricación de discos de IBM). Fujitsu sigue haciendo Discos portátiles y discos de servidores, pero dejó de hacer discos para ordenadores de escritorio en 2001, y el resto lo vendió a Western Digital. Toshiba es uno de los principales fabricantes de discos duros para portátiles de 2,5 pulgadas y 1,8 pulgadas. ExcelStor es un pequeño fabricante de discos duros.
Decenas de ex-fabricantes de discos duros han terminado con sus empresas fusionadas o han cerrado sus divisiones de discos duros, a medida que la capacidad de los dispositivos y la demanda de los productos aumentaron, los beneficios eran menores y el mercado sufrió una significativa consolidación a finales de los 80 y finales de los 90. La primera víctima en el mercado de los PC fue Computer Memories Inc. o CM; después de un incidente con 20 MB defectuoso en discos en 1985, La reputación de CMI nunca se recuperó, y salieron del mercado de los discos duros en 1987. Otro notable fallo fue de MiniScribe, quien quebró en 1990 después se descubrió que tenían en marcha un fraude e inflaban el número de ventas durante varios años. Otras muchas pequeñas compañías (como Kalok, Microscience, LaPine, Areal, Priam y PrairieTek) tampoco sobrevivieron a la expulsión, y habían desaparecido para 1993; Micropolis fue capaz de aguantar hasta 1997, y JTS, un recién llegado a escena, duro solo unos años y desapareció para 1999, después intentó fabricar discos duros en India. Su vuelta a la fama fue con la creación de un nuevo formato de tamaño de 3” para portátiles. Quantum and Integral también investigaron el formato de 3”, pero finalmente se dieron por vencidos. Rodime fue también un importante fabricante durante la década de los 80, pero dejó de hacer discos en la década de los 90 en medio de la reestructuración y ahora se concentra en la tecnología de la concesión de licencias; tienen varias patentes relacionadas con el formato de 3.5“.
•1988: Tandon Corporation vendió su división de fabricación de discos duros a Wstern Digital (WDC), el cual era un renombrado diseñador de controladores.
•1989: Seagate Technology compro el negocio de discos de alta calidad de Control Data, como parte del abandono de CDC en la creación de hardware.
•1990: Maxtor compro Mini Scribe que estaba en bancarrota, haciéndolo el núcleo de su división de discos de gama baja.
•1994: Quantum compro la división de almacenamiento de [Digital Equipment Corporation|DEC]] otorgando al usuario una gama de discos de alta calidad llamada ProDrive , igual que la gama tape drive de DLT
•1995: Conner Peripherals fue fundada por uno de los cofundadores de Seagate Technology's junto con personal de Mini Scribe, anunciaron un fusión con Seagate, la cual se completó a principios de 1996.
•1996: JTS se fusiono con Atari, permitiendo a JTS llevar a producción su gama de discos. Atari fue vendida a Hasbro en 1998, mientras que JTS sufrió una bancarrota en 1999.
•2000: Quantum vendió su división de discos a Maxtor para concentrarse en las unidades de cintas y los equipos de respaldo.
•2003: Siguiendo la controversia en los fallos masivos en su modelo Deskstar 75GXP , pioneer IBM vendió la mayor parte de su división de discos a Hitachi, renombrándose como Hitachi Global Storage Technologies (HGST).
•2003: Western Digital compro Read-Rite Corp, quien producía los cabezales utilizados en los discos duros, por 95.4 millones de $ en metálico.
o21 de diciembre de 2005: Seagate y Maxtor anuncian un acuerdo bajo el que Seagate adquiriría todo el stock de Maxtor por ciento noventa mil millones de $. Esta adquisición fue aprobada por los cuerpos regulatorios, y cerrada el 19 de mayo de 2006.
•2007 Julio: Western Digital (WDC) adquiere Komag U.S.A, un fabricante del material que recubre los platos de los discos duros, por ciento noventa mil millones de $.

Un disco RAM o unidad RAM es una unidad de disco que usa una zona de memoria RAM del sistema como almacenamiento secundario en lugar de un medio magnético (como los discos duros y las disqueteras) o memoria flash, implementada como un controlador de dispositivo más. El tiempo de acceso mejora drásticamente, debido a que la memoria RAM es varios órdenes de magnitud más rápida que las unidades de disco reales. Sin embargo, la volatilidad de la memoria RAM implica que los datos almacenados en un disco RAM se perderán si falla la alimentación (por ejemplo, cuando el ordenador se apaga). Los discos RAM suelen usarse para almacenar datos temporales o para guardar programas descomprimidos durante cortos periodos.
Los discos RAM fueron populares como unidades de arranque en los años 1980, cuando los discos duros eran caros y las disqueteras demasiado lentas, por lo que unos pocos sistemas, como el Amiga y el Apple IIgs, soportaban arrancar desde un disco RAM. A cambio de dedicar un poco de memoria principal, el sistema podía realizar un reinicio en caliente y volver al sistema operativo en pocos segundos en lugar de minutos. Algunos sistemas contaban con discos RAM alimentados por baterías, de forma que sus contenidos no se perdían cuando el sistema se apagaba.
La adecuada implementación de un caché de disco suele obviar las motivaciones relacionadas con el rendimiento que impulsan a usar un disco RAM, adoptando un papel parecido (acceso rápido a los datos que en realidad residen en un disco) sin sus varias desventajas (pérdida de datos en caso de apagado, particionado estático, etcétera). Los discos RAM son, sin embargo, indispensables en situaciones en las que un disco físico no está disponible o en las que el acceso o cambios a éste no es deseable (como en el caso de un LiveCD. También pueden usarse en dispositivos de tipo quiosco, en los que los cambios hechos al sistema no se guardan en el disco físico y la configuración original del sistema se carga de éste cada vez que el sistema es reiniciado.
Un disco duro (del inglés hard disk (HD)) es un disco magnético en el que puedes almacenar datos de ordenador. El disco duro es la parte de tu ordenador que contiene la información electrónica y donde se almacenan todos los programas (software). Es uno de los componentes del hardware más importantes dentro de tu PC.
El término duro se utiliza para diferenciarlo del disco flexible o disquete (floppy en inglés). Los discos duros pueden almacenar muchos más datos y son más rápidos que los disquetes. Por ejemplo, un disco duro puede llegar a almacenar más de 100 gigabytes, mientras que la mayoría de los disquetes tienen una memoria máxima de 1.4 megabytes.
Componentes de un disco duro:
Normalmente un disco duro consiste en varios discos o platos. Cada disco requiere dos cabezales de lectura/grabación, uno para cada lado. Todos los cabezales de lectura/grabación están unidos a un solo brazo de acceso, de modo que no puedan moverse independientemente. Cada disco tiene el mismo número de pistas, y a la parte de la pista que corta a través de todos los discos se le llama cilindro.
Características de un disco duro:
Las características que se deben tener en cuenta en un disco duro son:
•Tiempo medio de acceso: Tiempo medio que tarda la aguja en situarse en la pista y el sector deseado; es la suma del Tiempo medio de búsqueda (situarse en la pista), tiempo de lectura/escritura y la Latencia media (situarse en el sector).
•Tiempo medio de búsqueda: Tiempo medio que tarda la aguja en situarse en la pista deseada; es la mitad del tiempo empleado por la aguja en ir desde la pista más periférica hasta la más central del disco.
•Tiempo de lectura/escritura: Tiempo medio que tarda el disco en leer o escribir nueva información, el tiempo depende de la cantidad de información que se quiere leer o escribir, el tamaño de bloque, el numero de cabezales, el tiempo por vuelta y la cantidad de sectores por pista.
•Latencia media: Tiempo medio que tarda la aguja en situarse en el sector deseado; es la mitad del tiempo empleado en una rotación completa del disco.
•Velocidad de rotación: Revoluciones por minuto de los platos. A mayor velocidad de rotación, menor latencia media.
•Tasa de transferencia: Velocidad a la que puede transferir la información a la computadora una vez la aguja está situada en la pista y sector correctos. Puede ser velocidad sostenida o de pico.
Otras características son:
•Caché de pista: Es una memoria tipo RAM dentro del disco duro. Los discos duros de estado sólido utilizan cierto tipo de memorias construidas con semiconductores para almacenar la información. El uso de esta clase de discos generalmente se limita a
las supercomputadoras, por su elevado precio.
•Interfaz: Medio de comunicación entre el disco duro y la computadora. Puede ser IDE/ATA, SCSI, SATA, USB, Firewire, SAS
•Landz: Zona sobre las que aterrizan las cabezas una vez apagada la computadora.
Actualmente la nueva generación de discos duros utiliza la tecnología de grabación perpendicular (PMR), la cual permite mayor densidad de almacenamiento. También existen discos llamados "Ecológicos" (GP - Green Power), los cuales hacen un uso más eficiente de la energía. Se está empezando a observar que la Unidad de estado sólido es posible que termine sustituyendo al disco duro a largo plazo. También hay que añadir los nuevos discos duros basados en el tipo de memorias Flash, que algunas empresas, como ASUS, incorporó recientemente en sus modelos. Los mismos arrancan en 4GB a 512 GB.1...
Son muy rápidos ya que no tienen partes móviles y consumen menos energía. Todo esto les hace muy fiables y casi indestructibles. Un nuevo formato de discos duros basados en tarjetas de memorias. Sin embargo su costo por GB es aún muy elevado ya que el coste de un HD de 160 GB es equivalente a un SSD de 8 GB.
Los recursos tecnológicos y el saber hacer requeridos para el desarrollo y la producción de discos modernos implica que desde 2007, más del 98% de los discos duros del mundo son fabricados por un conjunto de grandes empresas: Seagate (que ahora es propietaria de Maxtor), Western Digital, Samsung e Hitachi (que es propietaria de la antigua división de fabricación de discos de IBM). Fujitsu sigue haciendo Discos portátiles y discos de servidores, pero dejó de hacer discos para ordenadores de escritorio en 2001, y el resto lo vendió a Western Digital. Toshiba es uno de los principales fabricantes de discos duros para portátiles de 2,5 pulgadas y 1,8 pulgadas. ExcelStor es un pequeño fabricante de discos duros.
Decenas de ex-fabricantes de discos duros han terminado con sus empresas fusionadas o han cerrado sus divisiones de discos duros, a medida que la capacidad de los dispositivos y la demanda de los productos aumentaron, los beneficios eran menores y el mercado sufrió una significativa consolidación a finales de los 80 y finales de los 90. La primera víctima en el mercado de los PC fue Computer Memories Inc. o CM; después de un incidente con 20 MB defectuoso en discos en 1985, La reputación de CMI nunca se recuperó, y salieron del mercado de los discos duros en 1987. Otro notable fallo fue de MiniScribe, quien quebró en 1990 después se descubrió que tenían en marcha un fraude e inflaban el número de ventas durante varios años. Otras muchas pequeñas compañías (como Kalok, Microscience, LaPine, Areal, Priam y PrairieTek) tampoco sobrevivieron a la expulsión, y habían desaparecido para 1993; Micropolis fue capaz de aguantar hasta 1997, y JTS, un recién llegado a escena, duro solo unos años y desapareció para 1999, después intentó fabricar discos duros en India. Su vuelta a la fama fue con la creación de un nuevo formato de tamaño de 3” para portátiles. Quantum and Integral también investigaron el formato de 3”, pero finalmente se dieron por vencidos. Rodime fue también un importante fabricante durante la década de los 80, pero dejó de hacer discos en la década de los 90 en medio de la reestructuración y ahora se concentra en la tecnología de la concesión de licencias; tienen varias patentes relacionadas con el formato de 3.5“.
•1988: Tandon Corporation vendió su división de fabricación de discos duros a Wstern Digital (WDC), el cual era un renombrado diseñador de controladores.
•1989: Seagate Technology compro el negocio de discos de alta calidad de Control Data, como parte del abandono de CDC en la creación de hardware.
•1990: Maxtor compro Mini Scribe que estaba en bancarrota, haciéndolo el núcleo de su división de discos de gama baja.
•1994: Quantum compro la división de almacenamiento de [Digital Equipment Corporation|DEC]] otorgando al usuario una gama de discos de alta calidad llamada ProDrive , igual que la gama tape drive de DLT
•1995: Conner Peripherals fue fundada por uno de los cofundadores de Seagate Technology's junto con personal de Mini Scribe, anunciaron un fusión con Seagate, la cual se completó a principios de 1996.
•1996: JTS se fusiono con Atari, permitiendo a JTS llevar a producción su gama de discos. Atari fue vendida a Hasbro en 1998, mientras que JTS sufrió una bancarrota en 1999.
•2000: Quantum vendió su división de discos a Maxtor para concentrarse en las unidades de cintas y los equipos de respaldo.
•2003: Siguiendo la controversia en los fallos masivos en su modelo Deskstar 75GXP , pioneer IBM vendió la mayor parte de su división de discos a Hitachi, renombrándose como Hitachi Global Storage Technologies (HGST).
•2003: Western Digital compro Read-Rite Corp, quien producía los cabezales utilizados en los discos duros, por 95.4 millones de $ en metálico.
o21 de diciembre de 2005: Seagate y Maxtor anuncian un acuerdo bajo el que Seagate adquiriría todo el stock de Maxtor por ciento noventa mil millones de $. Esta adquisición fue aprobada por los cuerpos regulatorios, y cerrada el 19 de mayo de 2006.
•2007 Julio: Western Digital (WDC) adquiere Komag U.S.A, un fabricante del material que recubre los platos de los discos duros, por ciento noventa mil millones de $.

5.4.1 HARDWARE DE DISCOS
Los discos están organizados en cilindros, pistas y sectores.
El número típico de sectores por pista varía entre 8 y 32 (o más).
Todos los sectores tienen igual número de bytes.
Los sectores cercanos a la orilla del disco serán mayores físicamente que los cercanos al anillo.
Un controlador puede realizar búsquedas en una o más unidades al mismo tiempo:
•Son las búsquedas traslapadas.
•Mientras el controlador y el software esperan el fin de una búsqueda en una unidad, el controlador puede iniciar una búsqueda en otra.
Muchos controladores pueden:
•Leer o escribir en una unidad.
•Buscar en otra.
Los controladores no pueden leer o escribir en dos unidades al mismo tiempo.

Los discos están organizados en cilindros, pistas y sectores.
El número típico de sectores por pista varía entre 8 y 32 (o más).
Todos los sectores tienen igual número de bytes.
Los sectores cercanos a la orilla del disco serán mayores físicamente que los cercanos al anillo.
Un controlador puede realizar búsquedas en una o más unidades al mismo tiempo:
•Son las búsquedas traslapadas.
•Mientras el controlador y el software esperan el fin de una búsqueda en una unidad, el controlador puede iniciar una búsqueda en otra.
Muchos controladores pueden:
•Leer o escribir en una unidad.
•Buscar en otra.
Los controladores no pueden leer o escribir en dos unidades al mismo tiempo.

5.4.2 SOFTWARE PARA DISCOS
En la mayoría de los discos, el tiempo de búsqueda supera al de retraso rotacional y al de transferencia, debido a ello, la reducción del tiempo promedio de búsqueda puede mejorar en gran medida el rendimiento del sistema.
Si el manejador del disco utiliza el algoritmo primero en llegar primero en ser atendido (FCFS), poco se puede hacer para mejorar el tiempo de búsqueda.
Es posible que mientras el brazo realiza una búsqueda para una solicitud, otros procesos generen otras solicitudes.
Muchos manejadores tienen una tabla:
•El índice es el número de cilindro.
•Incluye las solicitudes pendientes para cada cilindro enlazadas entre sí en una lista ligada.
•Cuando concluye una búsqueda, el manejador del disco tiene la opción de elegir la
siguiente solicitud a dar paso:
oSe atiende primero la solicitud más cercana, para minimizar el tiempo de búsqueda.
oEste algoritmo se denomina primero la búsqueda más corta (SSF: shor-test seek first).
oReduce a la mitad el número de movimientos del brazo en comparación con FCFS.
Ej. De SSF:
•Consideramos un disco de 40 cilindros.
•Se presenta una solicitud de lectura de un bloque en el cilindro 11.
•Durante la búsqueda, llegan solicitudes para los cilindros 1, 36, 16, 34, 9 y 12, en ese orden.
•La secuencia de búsqueda SSF será: 12, 9, 16, 1, 34, 36.
•Habrá un número de movimientos del brazo para un total de:
o111 cilindros según FCFS.
o61 cilindros según SSF.
El algoritmo SSF tiene el siguiente problema:
•El ingreso de nuevas solicitudes puede demorar la atención de las más antiguas.
•Con un disco muy cargado, el brazo tenderá a permanecer a la mitad del disco la mayoría del tiempo, como consecuencia de ello las solicitudes lejanas a la mitad del disco tendrán un mal servicio.
•Entran en conflicto los objetivos de:
oTiempo mínimo de respuesta.
oJusticia en la atención.
La solución a este problema la brinda el algoritmo del elevador (por su analogía con el ascensor o elevador):
•Se mantiene el movimiento del brazo en la misma dirección, hasta que no tiene más solicitudes pendientes en esa dirección; entonces cambia de dirección.
•El software debe conservar el bit de dirección actual.
Ej. Del algoritmo del elevador para el caso anterior, con el valor inicial arriba del bit de dirección:
•El orden de servicio a los cilindros es: 12, 16, 34, 36, 9 y 1.
•El número de movimientos del brazo corresponde a 60 cilindros.
El algoritmo del elevador:
•Ocasionalmente es mejor que el algoritmo SSF.
•Generalmente es peor que SSF.
•Dada cualquier colección de solicitudes, la cuota máxima del total de movimientos está fija, siendo el doble del número de cilindros.
Una variante consiste en rastrear siempre en la misma dirección:
•Luego de servir al cilindro con el número mayor:
oEl brazo pasa al cilindro de número menor con una solicitud pendiente.
oContinúa su movimiento hacia arriba.
Algunos controladores de disco permiten que el software inspeccione el número del
sector activo debajo del cabezal:
•Si dos o más solicitudes para el mismo cilindro están pendientes:
oEl manejador puede enviar una solicitud para el sector que pasará debajo del cabezal.
oSe pueden hacer solicitudes consecutivas de distintas pistas de un mismo cilindro,
sin generar un movimiento del brazo.
Cuando existen varias unidades, se debe tener una tabla de solicitudes pendientes para cada unidad.
Si una unidad está inactiva, deberá buscarse el cilindro siguiente necesario, si el controlador permite búsquedas traslapadas.
Cuando termina la transferencia actual se verifica si las unidades están en la
posición del cilindro correcto:
•Si una o más unidades lo están, se puede iniciar la siguiente transferencia en una unidad ya posicionada.
•Si ninguno de los brazos está posicionado, el manejador:
oDebe realizar una nueva búsqueda en la unidad que terminó la transferencia.
oDebe esperar hasta la siguiente interrupción para ver cuál brazo se posiciona primero.
Generalmente, las mejoras tecnológicas de los discos:
•Acortan los tiempos de búsqueda (seek).
•No acortan los tiempos de demora rotacional (search).
•En algunos discos, el tiempo promedio de búsqueda ya es menor que el retraso rotacional.
•El factor dominante será el retraso rotacional, por lo tanto, los algoritmos que optimizan los tiempos de búsqueda (como el algoritmo del elevador) perderán importancia frente a los algoritmos que optimicen el retraso rotacional.
Una tecnología importante es la que permite el trabajo conjunto de varios discos.
Una configuración interesante es la de treinta y ocho (38) unidades ejecutándose en paralelo.
Cuando se realiza una operación de lectura:
•Ingresan a la CPU 38 bit a la vez, uno por cada unidad.
•Los 38 bits conforman una palabra de 32 bits junto con 6 bits para verificación.
•Los bits 1, 2, 4, 8, 16 y 32 se utilizan como bits de paridad.
•La palabra de 38 bits se puede codificar mediante el código Hamming, que es un código corrector de errores.
•Si una unidad sale de servicio:
oSe pierde un bit de cada palabra.
oEl sistema puede continuar trabajando; se debe a que los códigos Hamming se pueden recuperar de un bit perdido.

En la mayoría de los discos, el tiempo de búsqueda supera al de retraso rotacional y al de transferencia, debido a ello, la reducción del tiempo promedio de búsqueda puede mejorar en gran medida el rendimiento del sistema.
Si el manejador del disco utiliza el algoritmo primero en llegar primero en ser atendido (FCFS), poco se puede hacer para mejorar el tiempo de búsqueda.
Es posible que mientras el brazo realiza una búsqueda para una solicitud, otros procesos generen otras solicitudes.
Muchos manejadores tienen una tabla:
•El índice es el número de cilindro.
•Incluye las solicitudes pendientes para cada cilindro enlazadas entre sí en una lista ligada.
•Cuando concluye una búsqueda, el manejador del disco tiene la opción de elegir la
siguiente solicitud a dar paso:
oSe atiende primero la solicitud más cercana, para minimizar el tiempo de búsqueda.
oEste algoritmo se denomina primero la búsqueda más corta (SSF: shor-test seek first).
oReduce a la mitad el número de movimientos del brazo en comparación con FCFS.
Ej. De SSF:
•Consideramos un disco de 40 cilindros.
•Se presenta una solicitud de lectura de un bloque en el cilindro 11.
•Durante la búsqueda, llegan solicitudes para los cilindros 1, 36, 16, 34, 9 y 12, en ese orden.
•La secuencia de búsqueda SSF será: 12, 9, 16, 1, 34, 36.
•Habrá un número de movimientos del brazo para un total de:
o111 cilindros según FCFS.
o61 cilindros según SSF.
El algoritmo SSF tiene el siguiente problema:
•El ingreso de nuevas solicitudes puede demorar la atención de las más antiguas.
•Con un disco muy cargado, el brazo tenderá a permanecer a la mitad del disco la mayoría del tiempo, como consecuencia de ello las solicitudes lejanas a la mitad del disco tendrán un mal servicio.
•Entran en conflicto los objetivos de:
oTiempo mínimo de respuesta.
oJusticia en la atención.
La solución a este problema la brinda el algoritmo del elevador (por su analogía con el ascensor o elevador):
•Se mantiene el movimiento del brazo en la misma dirección, hasta que no tiene más solicitudes pendientes en esa dirección; entonces cambia de dirección.
•El software debe conservar el bit de dirección actual.
Ej. Del algoritmo del elevador para el caso anterior, con el valor inicial arriba del bit de dirección:
•El orden de servicio a los cilindros es: 12, 16, 34, 36, 9 y 1.
•El número de movimientos del brazo corresponde a 60 cilindros.
El algoritmo del elevador:
•Ocasionalmente es mejor que el algoritmo SSF.
•Generalmente es peor que SSF.
•Dada cualquier colección de solicitudes, la cuota máxima del total de movimientos está fija, siendo el doble del número de cilindros.
Una variante consiste en rastrear siempre en la misma dirección:
•Luego de servir al cilindro con el número mayor:
oEl brazo pasa al cilindro de número menor con una solicitud pendiente.
oContinúa su movimiento hacia arriba.
Algunos controladores de disco permiten que el software inspeccione el número del
sector activo debajo del cabezal:
•Si dos o más solicitudes para el mismo cilindro están pendientes:
oEl manejador puede enviar una solicitud para el sector que pasará debajo del cabezal.
oSe pueden hacer solicitudes consecutivas de distintas pistas de un mismo cilindro,
sin generar un movimiento del brazo.
Cuando existen varias unidades, se debe tener una tabla de solicitudes pendientes para cada unidad.
Si una unidad está inactiva, deberá buscarse el cilindro siguiente necesario, si el controlador permite búsquedas traslapadas.
Cuando termina la transferencia actual se verifica si las unidades están en la
posición del cilindro correcto:
•Si una o más unidades lo están, se puede iniciar la siguiente transferencia en una unidad ya posicionada.
•Si ninguno de los brazos está posicionado, el manejador:
oDebe realizar una nueva búsqueda en la unidad que terminó la transferencia.
oDebe esperar hasta la siguiente interrupción para ver cuál brazo se posiciona primero.
Generalmente, las mejoras tecnológicas de los discos:
•Acortan los tiempos de búsqueda (seek).
•No acortan los tiempos de demora rotacional (search).
•En algunos discos, el tiempo promedio de búsqueda ya es menor que el retraso rotacional.
•El factor dominante será el retraso rotacional, por lo tanto, los algoritmos que optimizan los tiempos de búsqueda (como el algoritmo del elevador) perderán importancia frente a los algoritmos que optimicen el retraso rotacional.
Una tecnología importante es la que permite el trabajo conjunto de varios discos.
Una configuración interesante es la de treinta y ocho (38) unidades ejecutándose en paralelo.
Cuando se realiza una operación de lectura:
•Ingresan a la CPU 38 bit a la vez, uno por cada unidad.
•Los 38 bits conforman una palabra de 32 bits junto con 6 bits para verificación.
•Los bits 1, 2, 4, 8, 16 y 32 se utilizan como bits de paridad.
•La palabra de 38 bits se puede codificar mediante el código Hamming, que es un código corrector de errores.
•Si una unidad sale de servicio:
oSe pierde un bit de cada palabra.
oEl sistema puede continuar trabajando; se debe a que los códigos Hamming se pueden recuperar de un bit perdido.

5.5.2 SOFTWARE RELOJ
El software para reloj toma generalmente la forma de un manejador de dispositivo, aunque no es un dispositivo de bloque ni de carácter.
Los relojes más sencillos trabajan con la línea de corriente eléctrica de 110 o 220 voltios y provocan una interrupción por cada ciclo de voltaje, a 50 o 60 hz.
Otro tipo de relojes consta de tres componentes:
•Un oscilador de cristal, un contador y un registro.
•Una pieza de cristal de cuarzo se monta en una estructura bajo tensión:
oGenera una señal periódica de muy alta precisión, generalmente entre 5 y 100 mhz.
oLa señal se alimenta en el contador para que cuente en forma descendente hasta cero.
oCuando el contador llega a cero, provoca una interrupción de la CPU.
Los relojes programables tienen varios modos de operación:
•Modo de una instancia:
oCuando el reloj se inicializa, copia el valor del registro en el contador.
oDecrementa el contador en cada pulso del cristal.
oCuando el contador llega a cero provoca una interrupción y se detiene hasta ser nuevamente inicializado por el software.
•Modo de onda cuadrada:
oLuego de llegar a cero y provocar la interrupción, el registro se copia de manera automática en el contador.
oTodo el programa se repite en forma indefinida.
oLas interrupciones periódicas se llaman marcas del reloj.
La ventaja del reloj programable es que su frecuencia de interrupción puede ser controlada por el software.

El software para reloj toma generalmente la forma de un manejador de dispositivo, aunque no es un dispositivo de bloque ni de carácter.
Los relojes más sencillos trabajan con la línea de corriente eléctrica de 110 o 220 voltios y provocan una interrupción por cada ciclo de voltaje, a 50 o 60 hz.
Otro tipo de relojes consta de tres componentes:
•Un oscilador de cristal, un contador y un registro.
•Una pieza de cristal de cuarzo se monta en una estructura bajo tensión:
oGenera una señal periódica de muy alta precisión, generalmente entre 5 y 100 mhz.
oLa señal se alimenta en el contador para que cuente en forma descendente hasta cero.
oCuando el contador llega a cero, provoca una interrupción de la CPU.
Los relojes programables tienen varios modos de operación:
•Modo de una instancia:
oCuando el reloj se inicializa, copia el valor del registro en el contador.
oDecrementa el contador en cada pulso del cristal.
oCuando el contador llega a cero provoca una interrupción y se detiene hasta ser nuevamente inicializado por el software.
•Modo de onda cuadrada:
oLuego de llegar a cero y provocar la interrupción, el registro se copia de manera automática en el contador.
oTodo el programa se repite en forma indefinida.
oLas interrupciones periódicas se llaman marcas del reloj.
La ventaja del reloj programable es que su frecuencia de interrupción puede ser controlada por el software.

5.5.3 MANEJADOR DEL RELOJ
Las principales funciones del software manejador del reloj son:
•Mantener la hora del día o tiempo real.
•Evitar que los procesos se ejecuten durante más tiempo del permitido.
•Mantener un registro del uso de la CPU.
•Controlar llamadas al sistema tipo “alarm” por parte de los procesos del usuario.
•Proporcionar cronómetros guardianes de partes del propio sistema.
•Realizar resúmenes, monitoreo y recolección de estadísticas.
El software manejador del reloj puede tener que simular varios relojes virtuales con un único reloj físico.

Las principales funciones del software manejador del reloj son:
•Mantener la hora del día o tiempo real.
•Evitar que los procesos se ejecuten durante más tiempo del permitido.
•Mantener un registro del uso de la CPU.
•Controlar llamadas al sistema tipo “alarm” por parte de los procesos del usuario.
•Proporcionar cronómetros guardianes de partes del propio sistema.
•Realizar resúmenes, monitoreo y recolección de estadísticas.
El software manejador del reloj puede tener que simular varios relojes virtuales con un único reloj físico.

5.6 TERMINALES
Las terminales tienen gran número de formas distintas:
•El manejador de la terminal debe ocultar estas diferencias.
•La parte independiente del dispositivo en el S. O. y los programas del usuario no se tienen que reescribir para cada tipo de terminal.
Desde el punto de vista del S. O. se las puede clasificar en:
•Interfaz RS-232:
oHardcopy (terminales de impresión).
oTTY “de vidrio” (terminales de video).
oInteligente (computadoras con CPU y memoria).
•Interfaz mapeada a memoria:
oOrientada a caracteres.
oOrientada a bits.
Las terminales RS-232 poseen un teclado y un monitor que se comunican mediante una interfaz serial, un bit a la vez; las conversiones de bits a bytes y viceversa las efectúan los chips uart (transmisores - receptores asíncronos universales).
Las terminales mapeadas a memoria:
•No se comunican mediante una línea serial.
•Poseen una interfaz mediante una memoria especial llamada video RAM:
oForma parte del espacio de direcciones de la computadora.
oLa CPU se dirige a ella como al resto de la memoria.
oEn la tarjeta de video RAM hay un chip llamado controlador de video:
Extrae bytes del video RAM y genera la señal de video utilizada para manejar la pantalla.
El monitor genera un rayo de electrones que recorre la pantalla pintando líneas.
Cada línea está constituida por un cierto número de puntos o pixeles.
La señal del controlador de video modula el rayo de electrones y determina si un pixel debe estar o no iluminado.
Los monitores de color poseen tres rayos (rojo, verde y azul) que se modulan independientemente.
En las pantallas mapeadas a caracteres:
•Cada caracter en la pantalla equivale a dos caracteres de RAM:
oUno aloja al código (ASCII) del caracter por exhibir.
oOtro es el byte de atributo, necesario para determinar el color, el video inverso, el parpadeo, etc.
En las terminales mapeadas a bits:
•Se utiliza el mismo principio.
•Cada bit en el video RAM controla en forma directa un solo pixel de la pantalla.
•Permite una completa flexibilidad en los tipos y tamaños de caracteres, varias ventanas y gráficos arbitrarios.
Con las pantallas mapeadas a memoria, el teclado se desacopla totalmente de la pantalla:
•El teclado dispone de su propio manejador.
•El manejador del teclado puede operar en modo caracter o en modo línea.
Las terminales pueden operar con una estructura central de buffers o con buffers exclusivos para cada terminal.
Frecuentemente los manejadores de terminales soportan operaciones tales como:
•Mover el cursor hacia arriba, abajo, a la izquierda o a la derecha una posición.
•Mover el cursor a x, y.
•Insertar un caracter o una línea en el cursor.
•Eliminar un caracter o una línea en el cursor.
•Recorrer la pantalla hacia arriba o hacia abajo “n” líneas.
•Limpiar la pantalla desde el cursor hacia el final de la línea o hasta el final de la pantalla.
•Trabajar en modo de video inverso, subrayado, parpadeo o normal.
•Crear, construir, mover o controlar las ventanas.

Las terminales tienen gran número de formas distintas:
•El manejador de la terminal debe ocultar estas diferencias.
•La parte independiente del dispositivo en el S. O. y los programas del usuario no se tienen que reescribir para cada tipo de terminal.
Desde el punto de vista del S. O. se las puede clasificar en:
•Interfaz RS-232:
oHardcopy (terminales de impresión).
oTTY “de vidrio” (terminales de video).
oInteligente (computadoras con CPU y memoria).
•Interfaz mapeada a memoria:
oOrientada a caracteres.
oOrientada a bits.
Las terminales RS-232 poseen un teclado y un monitor que se comunican mediante una interfaz serial, un bit a la vez; las conversiones de bits a bytes y viceversa las efectúan los chips uart (transmisores - receptores asíncronos universales).
Las terminales mapeadas a memoria:
•No se comunican mediante una línea serial.
•Poseen una interfaz mediante una memoria especial llamada video RAM:
oForma parte del espacio de direcciones de la computadora.
oLa CPU se dirige a ella como al resto de la memoria.
oEn la tarjeta de video RAM hay un chip llamado controlador de video:
Extrae bytes del video RAM y genera la señal de video utilizada para manejar la pantalla.
El monitor genera un rayo de electrones que recorre la pantalla pintando líneas.
Cada línea está constituida por un cierto número de puntos o pixeles.
La señal del controlador de video modula el rayo de electrones y determina si un pixel debe estar o no iluminado.
Los monitores de color poseen tres rayos (rojo, verde y azul) que se modulan independientemente.
En las pantallas mapeadas a caracteres:
•Cada caracter en la pantalla equivale a dos caracteres de RAM:
oUno aloja al código (ASCII) del caracter por exhibir.
oOtro es el byte de atributo, necesario para determinar el color, el video inverso, el parpadeo, etc.
En las terminales mapeadas a bits:
•Se utiliza el mismo principio.
•Cada bit en el video RAM controla en forma directa un solo pixel de la pantalla.
•Permite una completa flexibilidad en los tipos y tamaños de caracteres, varias ventanas y gráficos arbitrarios.
Con las pantallas mapeadas a memoria, el teclado se desacopla totalmente de la pantalla:
•El teclado dispone de su propio manejador.
•El manejador del teclado puede operar en modo caracter o en modo línea.
Las terminales pueden operar con una estructura central de buffers o con buffers exclusivos para cada terminal.
Frecuentemente los manejadores de terminales soportan operaciones tales como:
•Mover el cursor hacia arriba, abajo, a la izquierda o a la derecha una posición.
•Mover el cursor a x, y.
•Insertar un caracter o una línea en el cursor.
•Eliminar un caracter o una línea en el cursor.
•Recorrer la pantalla hacia arriba o hacia abajo “n” líneas.
•Limpiar la pantalla desde el cursor hacia el final de la línea o hasta el final de la pantalla.
•Trabajar en modo de video inverso, subrayado, parpadeo o normal.
•Crear, construir, mover o controlar las ventanas.

5.6.1 HARDWARE DE TERMINALES
Un terminal IP es un dispositivo que permite realizar una comunicación utilizando una red IP ya sea mediante red de área local o a través de Internet. Generalmente nos referimos a un terminal IP en temas de Telefonía IP ya que son los principales dispositivos utilizados para realizar una comunicación de paquetes de datos en los que se transporta voz o vídeo.
CARACTERISTICAS
•Un terminal IP suele ser un dispositivo hardware con forma de teléfono, aunque con la diferencia de que utiliza una conexión de red de datos, en lugar de una conexión de red telefónica.
•Suelen tener más opciones y ventajas que un teléfono convencional. Al ser un sistema completamente digital y programable, suelen tener teclas especiales perfectamente configurables mediante un sistema de administración que puede ser accedido mediante web o mediante telnet.
•Algunos incluyen cámara de vídeo para poder realizar videoconferencias.
•Disponen de una dirección IP a la que poder acceder y mediante la que se puede configurar como si fuese un ordenador más. Por lo que, al considerarse un sistema más dentro de la red, suelen aplicárseles las características típicas de grandes redes: QoS o VLAN.
Ventajas frente a un sistema tradicional
•La ventaja principal estriba en que los terminales IP están preparados para utilizar una centralita digital de VoIP, lo cual abarata costes y permite una mayor versatilidad en cuando al manejo de las comunicaciones.
•La mayoría disponen de buzón de voz, desvíos de llamadas, configuración individual del dialplan y manejo de multitud de líneas individuales, para poder mantener varias conversaciones simultáneas.
•Suelen incorporar un sistema de música en espera y de transferencia de la llamada a otro terminal.
•Incluyen opciones para configurar las reglas de QoS o VLAN para mejorar la calidad del sonido y evitar cortes en una red con un alto Tráfico.
Hardware o Software
•Un terminal IP suele ser un dispositivo físico (similar al un teléfono normal), aunque también puede ser una aplicación que funciona en un sistema y que interactúa junto con micrófonos y auriculares/altavoz.
•Los terminales IP hardware evitan el choque de realizar una llamada de teléfono a través de otro dispositivo distinto a un teléfono normal.
•Los terminales IP software permiten reducir costes, a la vez que cuenta con la ventaja espacial de no tener un aparato más en la mesa.
ATA
•Los ATA son pequeños dispositivos que permiten conectar un teléfono analógico/RDSI a una red de VoIP.
•Disponen de un sistema de administración y gestión similar a los teléfonos IP por lo que disponen también de dirección IP, y las mismas ventajas que cualquier terminal IP.
Terminales Wireless
•Son similares a los teléfonos móviles (o celulares) y permiten utilizar redes inalámbricas para conectarse al servidor de VoIP o Gateway.
•Estos últimos aun no están muy desarrollados, pero pronto empezaremos a ver una gran expansión de los teléfonos móviles habituales con soporte Wi-Fi que permitirán utilizar la VoIP para realizar llamadas en lugar de las operadoras telefónicas tradicionales.
•Todos los periféricos conectados a la computadora que estamos usando para correr Linux son tratados como archivos especiales (device files) por el sistema operativo. Un periférico o dispositivo es una terminal, un disco duro, una impresora, un manejador de CD-ROM, o un modem. Todo lo que recibe o envía datos hacia el sistema operativo es un dispositivo.
•El concepto de tratar todo en el sistema como un dispositivo es uno de los beneficios de la arquitectura Unix. Cada dispositivo tiene un archivo especial llamado manejador de dispositivo (device file), el cual incluye todas las instrucciones necesarias para que Linux se comunique con el dispositivo. Cuando un nuevo dispositivo es desarrollado, puede ser usado por Linux escribiendo su manejador de dispositivo, el cual es usualmente un conjunto de instrucciones que explican como mandar y recibir datos.

Un terminal IP es un dispositivo que permite realizar una comunicación utilizando una red IP ya sea mediante red de área local o a través de Internet. Generalmente nos referimos a un terminal IP en temas de Telefonía IP ya que son los principales dispositivos utilizados para realizar una comunicación de paquetes de datos en los que se transporta voz o vídeo.
CARACTERISTICAS
•Un terminal IP suele ser un dispositivo hardware con forma de teléfono, aunque con la diferencia de que utiliza una conexión de red de datos, en lugar de una conexión de red telefónica.
•Suelen tener más opciones y ventajas que un teléfono convencional. Al ser un sistema completamente digital y programable, suelen tener teclas especiales perfectamente configurables mediante un sistema de administración que puede ser accedido mediante web o mediante telnet.
•Algunos incluyen cámara de vídeo para poder realizar videoconferencias.
•Disponen de una dirección IP a la que poder acceder y mediante la que se puede configurar como si fuese un ordenador más. Por lo que, al considerarse un sistema más dentro de la red, suelen aplicárseles las características típicas de grandes redes: QoS o VLAN.
Ventajas frente a un sistema tradicional
•La ventaja principal estriba en que los terminales IP están preparados para utilizar una centralita digital de VoIP, lo cual abarata costes y permite una mayor versatilidad en cuando al manejo de las comunicaciones.
•La mayoría disponen de buzón de voz, desvíos de llamadas, configuración individual del dialplan y manejo de multitud de líneas individuales, para poder mantener varias conversaciones simultáneas.
•Suelen incorporar un sistema de música en espera y de transferencia de la llamada a otro terminal.
•Incluyen opciones para configurar las reglas de QoS o VLAN para mejorar la calidad del sonido y evitar cortes en una red con un alto Tráfico.
Hardware o Software
•Un terminal IP suele ser un dispositivo físico (similar al un teléfono normal), aunque también puede ser una aplicación que funciona en un sistema y que interactúa junto con micrófonos y auriculares/altavoz.
•Los terminales IP hardware evitan el choque de realizar una llamada de teléfono a través de otro dispositivo distinto a un teléfono normal.
•Los terminales IP software permiten reducir costes, a la vez que cuenta con la ventaja espacial de no tener un aparato más en la mesa.
ATA
•Los ATA son pequeños dispositivos que permiten conectar un teléfono analógico/RDSI a una red de VoIP.
•Disponen de un sistema de administración y gestión similar a los teléfonos IP por lo que disponen también de dirección IP, y las mismas ventajas que cualquier terminal IP.
Terminales Wireless
•Son similares a los teléfonos móviles (o celulares) y permiten utilizar redes inalámbricas para conectarse al servidor de VoIP o Gateway.
•Estos últimos aun no están muy desarrollados, pero pronto empezaremos a ver una gran expansión de los teléfonos móviles habituales con soporte Wi-Fi que permitirán utilizar la VoIP para realizar llamadas en lugar de las operadoras telefónicas tradicionales.
•Todos los periféricos conectados a la computadora que estamos usando para correr Linux son tratados como archivos especiales (device files) por el sistema operativo. Un periférico o dispositivo es una terminal, un disco duro, una impresora, un manejador de CD-ROM, o un modem. Todo lo que recibe o envía datos hacia el sistema operativo es un dispositivo.
•El concepto de tratar todo en el sistema como un dispositivo es uno de los beneficios de la arquitectura Unix. Cada dispositivo tiene un archivo especial llamado manejador de dispositivo (device file), el cual incluye todas las instrucciones necesarias para que Linux se comunique con el dispositivo. Cuando un nuevo dispositivo es desarrollado, puede ser usado por Linux escribiendo su manejador de dispositivo, el cual es usualmente un conjunto de instrucciones que explican como mandar y recibir datos.

5.6.2 MANEJADORES
Los manejadores de dispositivos permiten al kernel de Linux incluir solo el sistema operativo y el soporte de software. Teniendo las instrucciones para comunicarse hacia los dispositivos dentro de un conjunto de archivos. Estos pueden ser buscados cuando son necesitados (en el caso de que raramente sean usados) o almacenados en memoria todo el tiempo cuando el sistema operativo es reiniciado. Los refinamientos hechos hacia un periférico, pequeños cambios hacia el archivo manejador del dispositivo pueden tener informado al sistema operativo de nuevas características y capacidades.
• Cuando una aplicación envía datos a un dispositivo, el kernel de Linux no tiene que preocuparse por el mecanismo. El kernel solo pasa la petición al manejador del dispositivo y deja que éste maneje las comunicaciones. Similarmente, cuando estamos tecleando, el manejador de dispositivo de la terminal acepta la acción y la pasa al shell, filtrando cualquier código especial que el kernel no conozca, traduciéndolo a un formato que el kernel pueda operar.
•Por omisión y convención Linux guarda los manejadores de dispositivos en el directorio /dev. Pueden guardarse los manejadores de dispositivos en cualquier parte del sistema de archivos, pero guardándolos en /dev hace obvio que son los manejadores de dispositivos.
•Diferencia entre dispositivos modo bloque y modo caracter.
•Cada tipo de dispositivo en el sistema Linux se comunica con la aplicación en una de las formas siguientes: carácter por carácter o como un conjunto de datos en un bloque de tamaño predefinido. Las terminales, impresoras y módems asíncronos son dispositivos modo carácter. Cuando se usa el modo caracter se envía uno a la vez y hace eco en la otra terminal. Los manejadores (device drivers) de disco duro y la mayoría de manejadores, usan el modo bloque, porque este es el camino más rápido para enviar o recibir grandes cantidades de información.
•Los archivos de dispositivo (device files) son llamados dispositivos modo carácter o dispositivos modo bloque, basados en la forma de comunicación.
•Cabe mencionar que los dispositivos que operan a modo carácter son distintos de los de modo bloque, en el aspecto de como el dispositivo maneja su búfer. Los dispositivos modo carácter hacen su propio búfer. Los dispositivos modo bloque, usualmente se comunican en bloques de 512 o 1024 bytes y el kernel se ocupa del búfer.
•Algunos periféricos necesitan usar archivos de dispositivo a modo bloque y carácter al mismo tiempo. Los manejadores de dispositivo manejan el modo carácter y el modo bloque a través de dos diferentes archivos de dispositivo. El archivo de dispositivo que se usa depende de cómo la aplicación quiera escribir o leer datos hacia el periférico.
•El archivo de dispositivo tiene todos los detalles de si el periférico opera a modo carácter o modo bloque. Una manera fácil de saber que tipo de modo utiliza un periférico es obtener un listado largo del archivo de dispositivo. El listado se obtiene con el comando 'ls -l' que muestra los permisos, dueño, grupo, etc... del archivo. Si el primer carácter es una b, indica que el periférico opera en modo bloque y una c indica que el periférico opera en modo carácter.
•Los archivos de dispositivos son usualmente nombrados indicando el tipo de dispositivo que son. La mayoría de terminales, por ejemplo, tienen un archivo de dispositivo con el nombre tty seguido por dos o más letras o números, tal como tty1, tty1A, o tty04. Las letras tty identifican al archivo como una terminal (tty es por teletype), y los números o letras identifican una terminal específica a la que es referida. Cuando se encuentran en el directorio llamado /dev, el nombre completo del archivo de dispositivo se convierte en /dev/tty01. El manejador del mouse conectado a su computadora se accesa a través del manejador /dev/mouse.
Los manejadores de dispositivos permiten al kernel de Linux incluir solo el sistema operativo y el soporte de software. Teniendo las instrucciones para comunicarse hacia los dispositivos dentro de un conjunto de archivos. Estos pueden ser buscados cuando son necesitados (en el caso de que raramente sean usados) o almacenados en memoria todo el tiempo cuando el sistema operativo es reiniciado. Los refinamientos hechos hacia un periférico, pequeños cambios hacia el archivo manejador del dispositivo pueden tener informado al sistema operativo de nuevas características y capacidades.
• Cuando una aplicación envía datos a un dispositivo, el kernel de Linux no tiene que preocuparse por el mecanismo. El kernel solo pasa la petición al manejador del dispositivo y deja que éste maneje las comunicaciones. Similarmente, cuando estamos tecleando, el manejador de dispositivo de la terminal acepta la acción y la pasa al shell, filtrando cualquier código especial que el kernel no conozca, traduciéndolo a un formato que el kernel pueda operar.
•Por omisión y convención Linux guarda los manejadores de dispositivos en el directorio /dev. Pueden guardarse los manejadores de dispositivos en cualquier parte del sistema de archivos, pero guardándolos en /dev hace obvio que son los manejadores de dispositivos.
•Diferencia entre dispositivos modo bloque y modo caracter.
•Cada tipo de dispositivo en el sistema Linux se comunica con la aplicación en una de las formas siguientes: carácter por carácter o como un conjunto de datos en un bloque de tamaño predefinido. Las terminales, impresoras y módems asíncronos son dispositivos modo carácter. Cuando se usa el modo caracter se envía uno a la vez y hace eco en la otra terminal. Los manejadores (device drivers) de disco duro y la mayoría de manejadores, usan el modo bloque, porque este es el camino más rápido para enviar o recibir grandes cantidades de información.
•Los archivos de dispositivo (device files) son llamados dispositivos modo carácter o dispositivos modo bloque, basados en la forma de comunicación.
•Cabe mencionar que los dispositivos que operan a modo carácter son distintos de los de modo bloque, en el aspecto de como el dispositivo maneja su búfer. Los dispositivos modo carácter hacen su propio búfer. Los dispositivos modo bloque, usualmente se comunican en bloques de 512 o 1024 bytes y el kernel se ocupa del búfer.
•Algunos periféricos necesitan usar archivos de dispositivo a modo bloque y carácter al mismo tiempo. Los manejadores de dispositivo manejan el modo carácter y el modo bloque a través de dos diferentes archivos de dispositivo. El archivo de dispositivo que se usa depende de cómo la aplicación quiera escribir o leer datos hacia el periférico.
•El archivo de dispositivo tiene todos los detalles de si el periférico opera a modo carácter o modo bloque. Una manera fácil de saber que tipo de modo utiliza un periférico es obtener un listado largo del archivo de dispositivo. El listado se obtiene con el comando 'ls -l' que muestra los permisos, dueño, grupo, etc... del archivo. Si el primer carácter es una b, indica que el periférico opera en modo bloque y una c indica que el periférico opera en modo carácter.
•Los archivos de dispositivos son usualmente nombrados indicando el tipo de dispositivo que son. La mayoría de terminales, por ejemplo, tienen un archivo de dispositivo con el nombre tty seguido por dos o más letras o números, tal como tty1, tty1A, o tty04. Las letras tty identifican al archivo como una terminal (tty es por teletype), y los números o letras identifican una terminal específica a la que es referida. Cuando se encuentran en el directorio llamado /dev, el nombre completo del archivo de dispositivo se convierte en /dev/tty01. El manejador del mouse conectado a su computadora se accesa a través del manejador /dev/mouse.
viernes, 20 de noviembre de 2009
4.1 GESTION DE MEMORIA

La memoria es uno de los principales recursos de la computadora, la cual debe de administrarse con mucho cuidado. Aunque actualmente la mayoría de los sistemas de cómputo cuentan con una alta capacidad de memoria, de igual manera las aplicaciones actuales tienen también altos requerimientos de memoria, lo que sigue generando escasez de memoria en los sistemas multitarea y/o multiusuario.
La parte del sistema operativo que administra la memoria se llama administrador de memoria y su labor consiste en llevar un registro de las partes de memoria que se estén utilizando y aquellas que no, con el fin de asignar espacio en memoria a los procesos cuando éstos la necesiten y liberándola cuando terminen, así como administrar el intercambio entre la memoria principal y el disco en los casos en los que la memoria principal no le pueda dar capacidad a todos los procesos que tienen necesidad de ella.
Los sistemas de administración de memoria se pueden clasificar en dos tipos: los que desplazan los procesos de la memoria principal al disco y viceversa durante la ejecución y los que no.
El propósito principal de una computadora es el de ejecutar programas, estos programas, junto con la información que accesan deben de estar en la memoria principal (al menos parcialmente) durante la ejecución.
Para optimizar el uso del CPU y de la memoria, el sistema operativo debe de tener varios procesos a la vez en la memoria principal, para lo cual dispone de varias opciones de administración tanto del procesador como de la memoria. La selección de uno de ellos depende principalmente del diseño del hardware para
4.1.1 ORGANIZACIÓN DE LA MEMORIA
La memoria real o principal es en donde son ejecutados los programas y procesos de una computadora y es el espacio real que existe en memoria para que se ejecuten los procesos. Por lo general esta memoria es de mayor costo que la memoria secundaria, pero el acceso a la información contenida en ella es de más rápido acceso. Solo la memoria cache es más rápida que la principal, pero su costo es a su vez mayor.
Memoria virtual
El término memoria virtual se asocia a dos conceptos que normalmente a parecen unidos:
1. El uso de almacenamiento secundario para ofrecer al conjunto de las aplicaciones la ilusión de tener mas memoria RAM de la que realmente hay en el sistema. Esta ilusión de existe tanto a nivel del sistema, es decir, teniendo en ejecución mas aplicaciones de las que realmente caben en la memoria principal, sin que por ello cada aplicación individual pueda usar mas memoria de la que realmente hay o incluso de forma mas general, ofreciendo a cada aplicación mas memoria de la que existe físicamente en la maquina.
2. Ofrecer a las aplicaciones la ilusión de que están solas en el sistema, y que por lo tanto, pueden usar el espacio de direcciones completo. Esta técnica facilita enormemente la generación de código, puesto que el compilador no tiene porque preocuparse sobre dónde residirá la aplicación cuando se ejecute.
Espacio De Direcciones
Los espacios de direcciones involucrados en el manejo de la memoria son de tres tipos:
• Direcciones físicas: son aquellas que referencian alguna posición en la memoria física.
• Direcciones lógicas : son las direcciones utilizadas por los procesos. Sufren una serie de transformaciones, realizadas por el procesador (la MMU), antes de convertirse en direcciones físicas.
• Direcciones lineales: direcciones lineales se obtienen a partir de direcciones lógicas tras haber aplicado una transformación dependiente de la arquitectura.
Los programas de usuario siempre tratan con direcciones virtuales ; nunca ven las direcciones físicas reales..
Unidad De Manejo De Memoria
La unidad de manejo de memoria (MMU) es parte del procesador. Sus funciones son:
• Convertir las direcciones lógicas emitidas por los procesos en direcciones físicas.
• Comprobar que la conversión se puede realizar. La dirección lógica podría no tener un dirección física asociada. Por ejemplo, la página correspondiente a una dirección se puede haber trasladado a una zona de almacenamiento secundario temporalmente.
• Comprobar que el proceso que intenta acceder a una cierta dirección de memoria tiene permisos para ello.
• La MMU se Inicializa para cada proceso del sistema. Esto permite que cada proceso pueda usar el rango completo de direcciones lógicas (memoria virtual), ya que las conversiones de estas direcciones serán distintas para cada proceso.
• En todos los procesos se configura la MMU para que la zona del núcleo solo se pueda acceder en modo privilegiado del procesador.
• La configuración correspondiente al espacio de memoria del núcleo es idéntica en todos los procesos.
3. Intercambio
El objetivo del intercambio es dar cabida a la ejecución de mas aplicaciones de las que pueden residir simultáneamente en la memoria del sistema:
Consiste en trasladar el código y los datos de un proceso completo de memoria al sistema de almacenamiento secundario , para cargar otro previamente almacenado, no permite a un proceso utilizar más memoria RAM de la que realmente existe en el sistema. Esta técnica puede ser ineficiente ya que se tiene que hacer el intercambio completo del proceso, aunque éste solo vaya a ejecutar una pequeña porción del código.
Durante el intercambio un proceso puede ser sacado temporalmente de memoria y llevado a un lugar especial del disco y posteriormente vuelto a memoria y continuada su ejecución..
El lugar de almacenamiento temporal suele ser un espacio suficientemente grande como para acomodar copias de las imágenes de memoria de todos los usuarios.
Asignación Contigua
La memoria principal normalmente se divide en dos particiones:
• Sistema operativo residente, normalmente en la parte baja de memoria con los vectores de interrupción.
• Procesos de usuario en la parte alta.
Asignación de partición simple:
Puede utilizarse un esquema de registro de relocalización y limite para proteger un proceso de usuario de otro y de cambios del código y datos del sistema operativo.
El registro de relocalización contiene la dirección contiene la dirección física más pequeña; el registro limite contiene el rango de las direcciones lógicas cada dirección lógica debe ser menor al registro limite
Asignación de particiones múltiples:
Bloques de distintos tamaños están distribuidos en l memoria, cuando llega un proceso se le asigna un hueco suficientemente grande para acomodarle.
El sistema operativo debe tener información sobre:
a. Particiones asignadas
b. Particiones libres (huecos)
Asignación de partición dinámica
El proceso de compactación es una instancia particular del problema de asignación de memoria dinámica, el cual es el cómo satisfacer una necesidad de tamaño n con una lista de huecos libres. Existen muchas soluciones para el problema. El conjunto de huecos es analizado para determinar cuál hueco es el más indicado para asignarse. Las estrategias más comunes para asignar algún hueco de la tabla son:
• Primer ajuste: Consiste en asignar el primer hueco con capacidad suficiente. La búsqueda puede iniciar ya sea al inicio o al final del conjunto de huecos o en donde terminó la última búsqueda. La búsqueda termina al encontrar un hueco lo suficientemente grande.
• Mejor ajuste: Busca asignar el espacio más pequeño de los espacios con capacidad suficiente. La búsqueda se debe de realizar en toda la tabla, a menos que la tabla esté ordenada por tamaño. Esta estrategia produce el menor desperdicio de memoria posible.
• Peor ajuste: Asigna el hueco más grande. Una vez más, se debe de buscar en toda la tabla de huecos a menos que esté organizada por tamaño. Esta estrategia produce los huecos de sobra más grandes, los cuales pudieran ser de más uso si llegan procesos de tamaño mediano que quepan en ellos.
Se ha demostrado mediante simulacros que tanto el primer y el mejor ajuste son mejores que el peor ajuste en cuanto a minimizar tanto el tiempo del almacenamiento. Ni el primer o el mejor ajuste es claramente el mejor en términos de uso de espacio, pero por lo general el primer ajuste es más rápido.
Problema: La fragmentación.
4. Fragmentación
La fragmentación es la memoria que queda desperdiciada al usar los métodos de gestión de memoria que se vieron en los métodos anteriores. Tanto el primer ajuste, como el mejor y el peor producen fragmentación externa.
La fragmentación es generada cuando durante el reemplazo de procesos quedan huecos entre dos o más procesos de manera no contigua y cada hueco no es capaz de soportar ningún proceso de la lista de espera.
La fragmentación puede ser:
• Fragmentación Externa: existe el espacio total de memoria para satisfacer un requerimiento, pero no es contigua.
• Fragmentación Interna: la memoria asignada puede ser ligeramente mayor que la requerida; esta referencia es interna a la partición, pero no se utiliza.
La fragmentación externa se puede reducir mediante la compactación para colocar toda la memoria libre en un solo gran bloque, pero está a solo es posible si la relocalización es dinámica y se hace en tiempo de ejecución.
5. Paginación
Es una técnica de manejo de memoria, en la cual el espacio de memoria se divide en secciones físicas de igual tamaño, denominadas marcos de página. Los programas se dividen en unidades lógicas, denominadas páginas, que tienen el mismo tamaño que los marcos de páginas. De esta forma, se puede cargar una página de información en cualquier marco de página.
Las páginas sirven como unidad de almacenamiento de información y de transferencia entre memoria principal y memoria auxiliar o secundaria. Cada marco se identifica por la dirección de marco, que está en la posición física de la primera palabra en el marco de página.
Las páginas de un programa necesitan estar contiguamente en memoria, aunque el programador lo observe de esta forma. Los mecanismos de paginación permiten la correspondencia correcta entre las direcciones virtuales (dadas por los programas) y las direcciones reales de la memoria que se reverencien.
Cada página consiste en z palabras contiguas; un espacio de direcciones N de un programa consiste de n paginas (0,1,2,3…n-1) (n*z direcciones virtuales) y el espacio de memoria consiste de m marcos de páginas (0,z,2z,…,(m-1)z)(m*z posiciones). Una dirección virtual a es equivalente a una dirección dada como una dupla (p, d), en la cual p es el número de la página y del número de la palabra dentro de la página, de acuerdo con la relación:
a=p*z+d (0<=d
d=a mod z (resto de divisor a/z)
En las maquinas que usan aritmética binaria, el calculo de (p, d) es trivial, si z es potencia de 2. Por ejemplo, si el campo de direcciones de la instrucción es de m bits (m>6), los cuatro bits mas significativos indican el numero de la pagina y los m-4 bits restantes, el desplazamiento.
Para tener el control de las páginas, debe mantenerse una tabla en memoria que se denomina tabla de Mapas de Pagina (PMT) para cada uno de los procesos.
Hasta ahora, los métodos que hemos visto de la administración de la memoria principal, nos han dejado con un problema: fragmentación, (huecos en la memoria que no pueden usarse debido a lo pequeño de su espacio) lo que nos provoca un desperdicio de memoria principal.
Una posible solución para la fragmentación externa es permitir que espacio de direcciones lógicas lleve a cabo un proceso en direcciones no contiguas, así permitiendo al proceso ubicarse en cualquier espacio de memoria física que esté disponible, aunque esté dividida. Una forma de implementar esta solución es a través del uso de un esquema de paginación. La paginación evita el considerable problema de ajustar los pedazos de memoria de tamaños variables que han sufrido los esquemas de manejo de memoria anteriores. Dado a sus ventajas sobre los métodos previos, la paginación, en sus diversas formas, es usada en muchos sistemas operativos.
Al utilizar la memoria virtual, las direcciones no pasan en forma directa al bus de memoria, sino que van a una unidad administradora de la memoria (MMU –Memory Management Unit). Estas direcciones generadas por los programas se llaman direcciones virtuales y conforman el hueco de direcciones virtuales. Este hueco se divide en unidades llamadas páginas. Las unidades correspondientes en la memoria física se llaman marcos para página o frames. Las páginas y los frames tienen siempre el mismo tamaño.
Tablas de páginas
Cada página tiene un número que se utiliza como índice en la tabla de páginas, lo que da por resultado el número del marco correspondiente a esa página virtual. Si el bit presente / ausente es 0, se provoca un señalamiento (trap) hacia el sistema operativo. Si el bit es 1, el número de marco que aparece en la tabla de páginas se copia en los bits de mayor orden del registro de salida, junto con el ajuste (offset) de 12 bits, el cual se copia sin modificaciones de la dirección virtual de entrada. Juntos forman una dirección física de 15 bits. El registro de salida se coloca entonces en el bus de la memoria como la dirección en la memoria física.
En teoría, la asociación de las direcciones virtuales con las físicas se efectúa según lo descrito. El número de página virtual se divide en un número de página virtual (los bits superiores)y un ajuste (los bits inferiores). El número de página virtual se utiliza como un índice en la tabla de páginas para encontrar la entrada de esa página virtual. El número de marco (si existe) se determina a partir de la tabla de páginas. El número de marco se asocia al extremo superior del ajuste y reemplaza al número de página virtual para formar una dirección física que se puede enviar a la memoria.
La finalidad de la tabla de páginas es asociar las páginas virtuales con los marcos. En términos matemáticos, la tabla de páginas es una función, cuyo argumento es el número de página virtual y como resultado el número del marco físico. Mediante el resultado de esta función, se puede reemplazar el campo de la página virtual de una dirección virtual por un campo de marco, lo que produce una dirección en la memoria física. Sin embargo hay que enfrentar dos aspectos fundamentales:
1. La tabla de páginas puede ser demasiado grande.
2. La asociación debe ser rápida.
El primer punto proviene del hecho de que las computadoras modernas utilizan direcciones virtuales de al menos 32 bits. Por ejemplo, si el tamaño de página es de 4K, un hueco de direcciones de 32 bits tiene un millón de páginas; en el caso de un hueco de direcciones de 64 bits, se tendría más información de la que uno quisiera contemplar.
El segundo punto es consecuencia del hecho de que la asociación virtual – física debe hacerse en cada referencia a la memoria. Una instrucción común tiene una palabra de instrucción y también un operando de memoria. Entonces es necesario hacer una, dos o más referencias a la tabla de páginas por cada instrucción.
Características de la paginación:
• El espacio de direcciones lógico de un proceso puede ser no contiguo.
• Se divide la memoria física en bloques de tamaño fijo llamados marcos (frames).
• Se divide la memoria en bloques de tamaño llamados páginas.
• Se mantiene información en los marcos libres.
• Para correr un programa de n paginas de tamaño, se necesitan encontrara n marcos y cargar el programa.
• Se establece una tabla de páginas para trasladar las direcciones lógicas a físicas.
• Se produce fragmentación interna.
Ventajas de la paginación
1. Es posible comenzar a ejecutar un programa, cargando solo una parte del mismo en memoria, y el resto se cargara bajo la solicitud.
2. No es necesario que las paginas estén contiguas en memoria, por lo que no se necesitan procesos de compactación cuando existen marcos de paginas libres dispersos en la memoria.
3. Es fácil controlar todas las páginas, ya que tienen el mismo tamaño.
4. El mecanismo de traducción de direcciones (DAT) permite separar los conceptos de espacio de direcciones y espacios de memoria. Todo el mecanismo es transparente al usuario.
5. Se libera al programador de la restricción de programar para un tamaño físico de memoria, con lo que s e aumenta su productividad. Se puede programar en función de una memoria mucho más grande a la existente.
6. Al no necesitarse cargar un programa completo en memoria para su ejecución, se puede aumentar el número de programas multiprogramándose.
7. Se elimina el problema de fragmentación externa.
Desventajas de la paginación
1. El costo de hardware y software se incrementa, por la nueva información que debe manejarse y el mecanismo de traducción de direcciones necesario. Se consume mucho mas recursos de memoria, tiempo en el CPU para su implantación.
2. Se deben reservar áreas de memoria para las PMT de los procesos. Al no ser fija el tamaño de estas, se crea un problema semejante al de los programas (como asignar un tamaño óptimo sin desperdicio de memoria, u "ovearhead" del procesador).
3. Aparece el problema de fragmentación interna. Así, si se requieren 5K para un programa, pero las paginas son de 4K, deberán asignárseles 2 paginas (8k), con lo que quedan 3K sin utilizar. La suma de los espacios libres dejados de esta forma puede ser mayor que el de varias paginas, pero no podrá ser utilizados. Debe asignarse un tamaño promedio a las páginas, evitando que si son muy pequeñas, se necesiten TABLAS BMT y PMT muy grandes, y si son muy grandes, se incremente el grado de fragmentación interna.
Traducción de Direcciones
La dirección generada por la CPU se divide en:
• Numero de pagina (p): utilizado como indice en la tabla de pagins que contiene la dirección base de cada pagina en la memoria fisica.
• Offset de la pagina (d): combinado con la dirección base dfine la direccion fisica que será enviada a la unidad de memoria.
Ejemplo de paginación:
6. Segmentación
Es un esquema de manejo de memoria mediante el cual la estructura del programa refleja su división lógica; llevándose a cabo una agrupación lógica de la información en bloques de tamaño variable denominados segmentos. Cada uno de ellos tienen información lógica del programa: subrutina, arreglo, etc. Luego, cada espacio de direcciones de programa consiste de una colección de segmentos, que generalmente reflejan la división lógica del programa.
La segmentación permite alcanzar los siguientes objetivos:
1. Modularidad de programas: cada rutina del programa puede ser un bloque sujeto a cambios y recopilaciones, sin afectar por ello al resto del programa.
2. Estructuras de datos de largo variable: ejm. Stack, donde cada estructura tiene su propio tamaño y este puede variar.
3. Protección: se puede proteger los módulos del segmento contra accesos no autorizados.
4. Comparición: dos o más procesos pueden ser un mismo segmento, bajo reglas de protección; aunque no sean propietarios de los mismos.
5. Enlace dinámico entre segmentos: puede evitarse realizar todo el proceso de enlace antes de comenzar a ejecutar un programa. Los enlaces se establecerán solo cuando sea necesario.
Ventajas de la segmentación
El esquema de segmentación ofrece las siguientes ventajas:
• El programador puede conocer las unidades lógicas de su programa, dándoles un tratamiento particular.
• Es posible compilar módulos separados como segmentos el enlace entre los segmentos puede suponer hasta tanto se haga una referencia entre segmentos.
• Debido a que es posible separar los módulos se hace más fácil la modificación de los mismos. Cambios dentro de un modulo no afecta al resto de los módulos.
• Es fácil el compartir segmentos.
• Es posible que los segmentos crezcan dinámicamente según las necesidades del programa en ejecución.
• Existe la posibilidad de definir segmentos que aun no existan. Así, no se asignara memoria, sino a partir del momento que sea necesario hacer usos del segmento. Un ejemplo de esto, serian los arreglos cuya dimensión no se conoce hasta tanto no se comienza a ejecutar el programa. En algunos casos, incluso podría retardar la asignación de memoria hasta el momento en el cual se referencia el arreglo u otra estructura de dato por primera vez.
Desventajas de la segmentación
• Hay un incremento en los costos de hardware y de software para llevar a cabo la implantación, así como un mayor consumo de recursos: memoria, tiempo de CPU, etc.
• Debido a que los segmentos tienen un tamaño variable se pueden presentar problemas de fragmentación externas, lo que puede ameritar un plan de reubicación de segmentos en memoria principal.
• Se complica el manejo de memoria virtual, ya que los discos almacenan la información en bloques de tamaños fijos, mientras los segmentos son de tamaño variable. Esto hace necesaria la existencia de mecanismos más costosos que los existentes para paginación.
• Al permitir que los segmentos varíen de tamaño, puede ser necesarios planes de reubicación a nivel de los discos, si los segmentos son devueltos a dicho dispositivo; lo que conlleva a nuevos costos.
• No se puede garantizar, que al salir un segmento de la memoria, este pueda ser traído fácilmente de nuevo, ya que será necesario encontrar nuevamente un área de memoria libre ajustada a su tamaño.
• La comparticion de segmentos permite ahorrar memoria, pero requiere de mecanismos adicionales da hardware y software.
Estas desventajas tratan de ser minimizadas, bajo la técnica conocida como Segmentación paginada.
7. Segmentación Paginada
Paginación y segmentación son técnicas diferentes, cada una de las cuales busca brindar las ventajas enunciadas anteriormente.
Para la segmentación se necesita que estén cargadas en memoria, áreas de tamaños variables. Si se requiere cargar un segmento en memoria; que antes estuvo en ella y fue removido a memoria secundaria; se necesita encontrar una región de la memoria lo suficientemente grande para contenerlo, lo cual no es siempre factible; en cambio "recargar" una pagina implica solo encontrar un merco de pagina disponible.
A nivel de paginación, si quiere referenciar en forma cíclicas n paginas, estas deberán ser cargadas una a una generándose varias interrupciones por fallas de paginas; bajo segmentación, esta pagina podría conformar un solo segmento, ocurriendo una sola interrupción, por falla de segmento. No obstante, si bajo segmentación, se desea acceder un área muy pequeña dentro de un segmento muy grande, este deberá cargarse completamente en memoria, desperdiciándose memoria; bajo paginación solo se cargara la página que contiene los ítems referenciados.
Puede hacerse una combinación de segmentación y paginación para obtener las ventajas de ambas. En lugar de tratar un segmento como una unidad contigua, este puede dividirse en páginas. Cada segmento puede ser descrito por su propia tabla de páginas.
Los segmentos son usualmente múltiplos de páginas en tamaño, y no es necesario que todas las páginas se encuentren en memoria principal a la vez; además las páginas de un mismo segmento, aunque se encuentren contiguas en memoria virtual; no necesitan estarlo en memoria real.
Las direcciones tienen tres componentes: (s, p,d), donde la primera indica el numero del segmento, la segunda el numero de la pagina dentro del segmento y la tercera el desplazamiento dentro de la pagina. Se deberán usar varias tablas:
• SMT (tabla de mapas de segmentos): una para cada proceso. En cada entrada de la SMT se almacena la información descrita bajo segmentación pura, pero en el campo de dirección se indicara la dirección de la PMT (tabla de mapas de páginas) que describe a las diferentes páginas de cada segmento.
• PMT (tabla de mapas de páginas): una por segmento; cada entrada de la PMT describe una página de un segmento; en la forma que se presento la pagina pura.
• TBM (tabla de bloques de memoria): para controlar asignación de páginas por parte del sistema operativo.
• JT (tabla de Jobs): que contiene las direcciones de comienzo de cada una de las SMT de los procesos que se ejecutan en memoria.
En el caso, de que un segmento sea de tamaño inferior o igual al de una pagina, no se necesita tener la correspondiente PMT, actuándose en igual forma que bajo segmentación pura; puede arreglarse un bit adicional (S) a cada entrada de la SMT, que indicara si el segmento esta paginado o no.
Ventajas de la segmentación paginada
El esquema de segmentación paginada tiene todas las ventajas de la segmentación y la paginación:
• Debido a que los espacios de memorias son segmentados, se garantiza la facilidad de implantar la comparticion y enlace.
• Como los espacios de memoria son paginados, se simplifican las estrategias de almacenamiento.
• Se elimina el problema de la fragmentación externa y la necesidad de compactación.
Desventajas de la segmentación paginada
• Las tres componentes de la dirección y el proceso de formación de direcciones hace que se incremente el costo de su implantación. El costo es mayor que en el caso de de segmentación pura o paginación pura.
• Se hace necesario mantener un número mayor de tablas en memoria, lo que implica un mayor costo de almacenamiento.
Sigue existiendo el problema de fragmentación interna de todas- o casi- todas las páginas finales de cada uno de los segmentos. Bajo paginación pura se desperdician solo la última página asignada, mientras que bajo segmentación – paginada el desperdicio puede ocurrir en todos los segmentos asignados.
8. Conclusiones
Para concluir se entiende que:
• En la memoria principal son ejecutados los programas y procesos de una computadora y es el espacio real que existe en memoria para que se ejecuten los procesos.
• La memoria virtual es aquella que le ofrece a las aplicaciones la ilusión de que están solas en el sistema y que pueden usar el espacio de direcciones completo.
• Las direcciones de memoria son de tres tipo: físicas, lógicas y lineales.
• El objetivo del intercambio es dar cabida a la ejecución de mas aplicaciones de las que pueden residir simultáneamente en la memoria del sistema.
• Las asignación consiste en determinar cual espacio vacío en la memoria principal es el mas indicado para ser asignado a un proceso.
• Las estrategias mas comunes para asignar espacios vacíos (huecos) son: primer ajuste, mejor ajuste, peor ajuste.
• La fragmentación es la memoria que queda desperdiciada al usar los métodos de gestión de memoria tal como la asignación.
• La fragmentación puede ser interna o externa.
• La paginación es una técnica de gestión de memoria en la cual el espacio de memoria se divide en secciones físicas de igual tamaño llamadas marcos de pagina, las cuales sirven como unidad de almacenamiento de información.
• La segmentación es un esquema de manejo de memoria mediante el cual la estructura del programa refleja su división lógica; llevándose a cabo una agrupación lógica de la información en bloques de tamaño variable denominados segmentos.
Memoria virtual
El término memoria virtual se asocia a dos conceptos que normalmente a parecen unidos:
1. El uso de almacenamiento secundario para ofrecer al conjunto de las aplicaciones la ilusión de tener mas memoria RAM de la que realmente hay en el sistema. Esta ilusión de existe tanto a nivel del sistema, es decir, teniendo en ejecución mas aplicaciones de las que realmente caben en la memoria principal, sin que por ello cada aplicación individual pueda usar mas memoria de la que realmente hay o incluso de forma mas general, ofreciendo a cada aplicación mas memoria de la que existe físicamente en la maquina.
2. Ofrecer a las aplicaciones la ilusión de que están solas en el sistema, y que por lo tanto, pueden usar el espacio de direcciones completo. Esta técnica facilita enormemente la generación de código, puesto que el compilador no tiene porque preocuparse sobre dónde residirá la aplicación cuando se ejecute.
Espacio De Direcciones
Los espacios de direcciones involucrados en el manejo de la memoria son de tres tipos:
• Direcciones físicas: son aquellas que referencian alguna posición en la memoria física.
• Direcciones lógicas : son las direcciones utilizadas por los procesos. Sufren una serie de transformaciones, realizadas por el procesador (la MMU), antes de convertirse en direcciones físicas.
• Direcciones lineales: direcciones lineales se obtienen a partir de direcciones lógicas tras haber aplicado una transformación dependiente de la arquitectura.
Los programas de usuario siempre tratan con direcciones virtuales ; nunca ven las direcciones físicas reales..
Unidad De Manejo De Memoria
La unidad de manejo de memoria (MMU) es parte del procesador. Sus funciones son:
• Convertir las direcciones lógicas emitidas por los procesos en direcciones físicas.
• Comprobar que la conversión se puede realizar. La dirección lógica podría no tener un dirección física asociada. Por ejemplo, la página correspondiente a una dirección se puede haber trasladado a una zona de almacenamiento secundario temporalmente.
• Comprobar que el proceso que intenta acceder a una cierta dirección de memoria tiene permisos para ello.
• La MMU se Inicializa para cada proceso del sistema. Esto permite que cada proceso pueda usar el rango completo de direcciones lógicas (memoria virtual), ya que las conversiones de estas direcciones serán distintas para cada proceso.
• En todos los procesos se configura la MMU para que la zona del núcleo solo se pueda acceder en modo privilegiado del procesador.
• La configuración correspondiente al espacio de memoria del núcleo es idéntica en todos los procesos.
3. Intercambio
El objetivo del intercambio es dar cabida a la ejecución de mas aplicaciones de las que pueden residir simultáneamente en la memoria del sistema:
Consiste en trasladar el código y los datos de un proceso completo de memoria al sistema de almacenamiento secundario , para cargar otro previamente almacenado, no permite a un proceso utilizar más memoria RAM de la que realmente existe en el sistema. Esta técnica puede ser ineficiente ya que se tiene que hacer el intercambio completo del proceso, aunque éste solo vaya a ejecutar una pequeña porción del código.
Durante el intercambio un proceso puede ser sacado temporalmente de memoria y llevado a un lugar especial del disco y posteriormente vuelto a memoria y continuada su ejecución..
El lugar de almacenamiento temporal suele ser un espacio suficientemente grande como para acomodar copias de las imágenes de memoria de todos los usuarios.
Asignación Contigua
La memoria principal normalmente se divide en dos particiones:
• Sistema operativo residente, normalmente en la parte baja de memoria con los vectores de interrupción.
• Procesos de usuario en la parte alta.
Asignación de partición simple:
Puede utilizarse un esquema de registro de relocalización y limite para proteger un proceso de usuario de otro y de cambios del código y datos del sistema operativo.
El registro de relocalización contiene la dirección contiene la dirección física más pequeña; el registro limite contiene el rango de las direcciones lógicas cada dirección lógica debe ser menor al registro limite
Asignación de particiones múltiples:
Bloques de distintos tamaños están distribuidos en l memoria, cuando llega un proceso se le asigna un hueco suficientemente grande para acomodarle.
El sistema operativo debe tener información sobre:
a. Particiones asignadas
b. Particiones libres (huecos)
Asignación de partición dinámica
El proceso de compactación es una instancia particular del problema de asignación de memoria dinámica, el cual es el cómo satisfacer una necesidad de tamaño n con una lista de huecos libres. Existen muchas soluciones para el problema. El conjunto de huecos es analizado para determinar cuál hueco es el más indicado para asignarse. Las estrategias más comunes para asignar algún hueco de la tabla son:
• Primer ajuste: Consiste en asignar el primer hueco con capacidad suficiente. La búsqueda puede iniciar ya sea al inicio o al final del conjunto de huecos o en donde terminó la última búsqueda. La búsqueda termina al encontrar un hueco lo suficientemente grande.
• Mejor ajuste: Busca asignar el espacio más pequeño de los espacios con capacidad suficiente. La búsqueda se debe de realizar en toda la tabla, a menos que la tabla esté ordenada por tamaño. Esta estrategia produce el menor desperdicio de memoria posible.
• Peor ajuste: Asigna el hueco más grande. Una vez más, se debe de buscar en toda la tabla de huecos a menos que esté organizada por tamaño. Esta estrategia produce los huecos de sobra más grandes, los cuales pudieran ser de más uso si llegan procesos de tamaño mediano que quepan en ellos.
Se ha demostrado mediante simulacros que tanto el primer y el mejor ajuste son mejores que el peor ajuste en cuanto a minimizar tanto el tiempo del almacenamiento. Ni el primer o el mejor ajuste es claramente el mejor en términos de uso de espacio, pero por lo general el primer ajuste es más rápido.
Problema: La fragmentación.
4. Fragmentación
La fragmentación es la memoria que queda desperdiciada al usar los métodos de gestión de memoria que se vieron en los métodos anteriores. Tanto el primer ajuste, como el mejor y el peor producen fragmentación externa.
La fragmentación es generada cuando durante el reemplazo de procesos quedan huecos entre dos o más procesos de manera no contigua y cada hueco no es capaz de soportar ningún proceso de la lista de espera.
La fragmentación puede ser:
• Fragmentación Externa: existe el espacio total de memoria para satisfacer un requerimiento, pero no es contigua.
• Fragmentación Interna: la memoria asignada puede ser ligeramente mayor que la requerida; esta referencia es interna a la partición, pero no se utiliza.
La fragmentación externa se puede reducir mediante la compactación para colocar toda la memoria libre en un solo gran bloque, pero está a solo es posible si la relocalización es dinámica y se hace en tiempo de ejecución.
5. Paginación
Es una técnica de manejo de memoria, en la cual el espacio de memoria se divide en secciones físicas de igual tamaño, denominadas marcos de página. Los programas se dividen en unidades lógicas, denominadas páginas, que tienen el mismo tamaño que los marcos de páginas. De esta forma, se puede cargar una página de información en cualquier marco de página.
Las páginas sirven como unidad de almacenamiento de información y de transferencia entre memoria principal y memoria auxiliar o secundaria. Cada marco se identifica por la dirección de marco, que está en la posición física de la primera palabra en el marco de página.
Las páginas de un programa necesitan estar contiguamente en memoria, aunque el programador lo observe de esta forma. Los mecanismos de paginación permiten la correspondencia correcta entre las direcciones virtuales (dadas por los programas) y las direcciones reales de la memoria que se reverencien.
Cada página consiste en z palabras contiguas; un espacio de direcciones N de un programa consiste de n paginas (0,1,2,3…n-1) (n*z direcciones virtuales) y el espacio de memoria consiste de m marcos de páginas (0,z,2z,…,(m-1)z)(m*z posiciones). Una dirección virtual a es equivalente a una dirección dada como una dupla (p, d), en la cual p es el número de la página y del número de la palabra dentro de la página, de acuerdo con la relación:
a=p*z+d (0<=d
d=a mod z (resto de divisor a/z)
En las maquinas que usan aritmética binaria, el calculo de (p, d) es trivial, si z es potencia de 2. Por ejemplo, si el campo de direcciones de la instrucción es de m bits (m>6), los cuatro bits mas significativos indican el numero de la pagina y los m-4 bits restantes, el desplazamiento.
Para tener el control de las páginas, debe mantenerse una tabla en memoria que se denomina tabla de Mapas de Pagina (PMT) para cada uno de los procesos.
Hasta ahora, los métodos que hemos visto de la administración de la memoria principal, nos han dejado con un problema: fragmentación, (huecos en la memoria que no pueden usarse debido a lo pequeño de su espacio) lo que nos provoca un desperdicio de memoria principal.
Una posible solución para la fragmentación externa es permitir que espacio de direcciones lógicas lleve a cabo un proceso en direcciones no contiguas, así permitiendo al proceso ubicarse en cualquier espacio de memoria física que esté disponible, aunque esté dividida. Una forma de implementar esta solución es a través del uso de un esquema de paginación. La paginación evita el considerable problema de ajustar los pedazos de memoria de tamaños variables que han sufrido los esquemas de manejo de memoria anteriores. Dado a sus ventajas sobre los métodos previos, la paginación, en sus diversas formas, es usada en muchos sistemas operativos.
Al utilizar la memoria virtual, las direcciones no pasan en forma directa al bus de memoria, sino que van a una unidad administradora de la memoria (MMU –Memory Management Unit). Estas direcciones generadas por los programas se llaman direcciones virtuales y conforman el hueco de direcciones virtuales. Este hueco se divide en unidades llamadas páginas. Las unidades correspondientes en la memoria física se llaman marcos para página o frames. Las páginas y los frames tienen siempre el mismo tamaño.
Tablas de páginas
Cada página tiene un número que se utiliza como índice en la tabla de páginas, lo que da por resultado el número del marco correspondiente a esa página virtual. Si el bit presente / ausente es 0, se provoca un señalamiento (trap) hacia el sistema operativo. Si el bit es 1, el número de marco que aparece en la tabla de páginas se copia en los bits de mayor orden del registro de salida, junto con el ajuste (offset) de 12 bits, el cual se copia sin modificaciones de la dirección virtual de entrada. Juntos forman una dirección física de 15 bits. El registro de salida se coloca entonces en el bus de la memoria como la dirección en la memoria física.
En teoría, la asociación de las direcciones virtuales con las físicas se efectúa según lo descrito. El número de página virtual se divide en un número de página virtual (los bits superiores)y un ajuste (los bits inferiores). El número de página virtual se utiliza como un índice en la tabla de páginas para encontrar la entrada de esa página virtual. El número de marco (si existe) se determina a partir de la tabla de páginas. El número de marco se asocia al extremo superior del ajuste y reemplaza al número de página virtual para formar una dirección física que se puede enviar a la memoria.
La finalidad de la tabla de páginas es asociar las páginas virtuales con los marcos. En términos matemáticos, la tabla de páginas es una función, cuyo argumento es el número de página virtual y como resultado el número del marco físico. Mediante el resultado de esta función, se puede reemplazar el campo de la página virtual de una dirección virtual por un campo de marco, lo que produce una dirección en la memoria física. Sin embargo hay que enfrentar dos aspectos fundamentales:
1. La tabla de páginas puede ser demasiado grande.
2. La asociación debe ser rápida.
El primer punto proviene del hecho de que las computadoras modernas utilizan direcciones virtuales de al menos 32 bits. Por ejemplo, si el tamaño de página es de 4K, un hueco de direcciones de 32 bits tiene un millón de páginas; en el caso de un hueco de direcciones de 64 bits, se tendría más información de la que uno quisiera contemplar.
El segundo punto es consecuencia del hecho de que la asociación virtual – física debe hacerse en cada referencia a la memoria. Una instrucción común tiene una palabra de instrucción y también un operando de memoria. Entonces es necesario hacer una, dos o más referencias a la tabla de páginas por cada instrucción.
Características de la paginación:
• El espacio de direcciones lógico de un proceso puede ser no contiguo.
• Se divide la memoria física en bloques de tamaño fijo llamados marcos (frames).
• Se divide la memoria en bloques de tamaño llamados páginas.
• Se mantiene información en los marcos libres.
• Para correr un programa de n paginas de tamaño, se necesitan encontrara n marcos y cargar el programa.
• Se establece una tabla de páginas para trasladar las direcciones lógicas a físicas.
• Se produce fragmentación interna.
Ventajas de la paginación
1. Es posible comenzar a ejecutar un programa, cargando solo una parte del mismo en memoria, y el resto se cargara bajo la solicitud.
2. No es necesario que las paginas estén contiguas en memoria, por lo que no se necesitan procesos de compactación cuando existen marcos de paginas libres dispersos en la memoria.
3. Es fácil controlar todas las páginas, ya que tienen el mismo tamaño.
4. El mecanismo de traducción de direcciones (DAT) permite separar los conceptos de espacio de direcciones y espacios de memoria. Todo el mecanismo es transparente al usuario.
5. Se libera al programador de la restricción de programar para un tamaño físico de memoria, con lo que s e aumenta su productividad. Se puede programar en función de una memoria mucho más grande a la existente.
6. Al no necesitarse cargar un programa completo en memoria para su ejecución, se puede aumentar el número de programas multiprogramándose.
7. Se elimina el problema de fragmentación externa.
Desventajas de la paginación
1. El costo de hardware y software se incrementa, por la nueva información que debe manejarse y el mecanismo de traducción de direcciones necesario. Se consume mucho mas recursos de memoria, tiempo en el CPU para su implantación.
2. Se deben reservar áreas de memoria para las PMT de los procesos. Al no ser fija el tamaño de estas, se crea un problema semejante al de los programas (como asignar un tamaño óptimo sin desperdicio de memoria, u "ovearhead" del procesador).
3. Aparece el problema de fragmentación interna. Así, si se requieren 5K para un programa, pero las paginas son de 4K, deberán asignárseles 2 paginas (8k), con lo que quedan 3K sin utilizar. La suma de los espacios libres dejados de esta forma puede ser mayor que el de varias paginas, pero no podrá ser utilizados. Debe asignarse un tamaño promedio a las páginas, evitando que si son muy pequeñas, se necesiten TABLAS BMT y PMT muy grandes, y si son muy grandes, se incremente el grado de fragmentación interna.
Traducción de Direcciones
La dirección generada por la CPU se divide en:
• Numero de pagina (p): utilizado como indice en la tabla de pagins que contiene la dirección base de cada pagina en la memoria fisica.
• Offset de la pagina (d): combinado con la dirección base dfine la direccion fisica que será enviada a la unidad de memoria.
Ejemplo de paginación:
6. Segmentación
Es un esquema de manejo de memoria mediante el cual la estructura del programa refleja su división lógica; llevándose a cabo una agrupación lógica de la información en bloques de tamaño variable denominados segmentos. Cada uno de ellos tienen información lógica del programa: subrutina, arreglo, etc. Luego, cada espacio de direcciones de programa consiste de una colección de segmentos, que generalmente reflejan la división lógica del programa.
La segmentación permite alcanzar los siguientes objetivos:
1. Modularidad de programas: cada rutina del programa puede ser un bloque sujeto a cambios y recopilaciones, sin afectar por ello al resto del programa.
2. Estructuras de datos de largo variable: ejm. Stack, donde cada estructura tiene su propio tamaño y este puede variar.
3. Protección: se puede proteger los módulos del segmento contra accesos no autorizados.
4. Comparición: dos o más procesos pueden ser un mismo segmento, bajo reglas de protección; aunque no sean propietarios de los mismos.
5. Enlace dinámico entre segmentos: puede evitarse realizar todo el proceso de enlace antes de comenzar a ejecutar un programa. Los enlaces se establecerán solo cuando sea necesario.
Ventajas de la segmentación
El esquema de segmentación ofrece las siguientes ventajas:
• El programador puede conocer las unidades lógicas de su programa, dándoles un tratamiento particular.
• Es posible compilar módulos separados como segmentos el enlace entre los segmentos puede suponer hasta tanto se haga una referencia entre segmentos.
• Debido a que es posible separar los módulos se hace más fácil la modificación de los mismos. Cambios dentro de un modulo no afecta al resto de los módulos.
• Es fácil el compartir segmentos.
• Es posible que los segmentos crezcan dinámicamente según las necesidades del programa en ejecución.
• Existe la posibilidad de definir segmentos que aun no existan. Así, no se asignara memoria, sino a partir del momento que sea necesario hacer usos del segmento. Un ejemplo de esto, serian los arreglos cuya dimensión no se conoce hasta tanto no se comienza a ejecutar el programa. En algunos casos, incluso podría retardar la asignación de memoria hasta el momento en el cual se referencia el arreglo u otra estructura de dato por primera vez.
Desventajas de la segmentación
• Hay un incremento en los costos de hardware y de software para llevar a cabo la implantación, así como un mayor consumo de recursos: memoria, tiempo de CPU, etc.
• Debido a que los segmentos tienen un tamaño variable se pueden presentar problemas de fragmentación externas, lo que puede ameritar un plan de reubicación de segmentos en memoria principal.
• Se complica el manejo de memoria virtual, ya que los discos almacenan la información en bloques de tamaños fijos, mientras los segmentos son de tamaño variable. Esto hace necesaria la existencia de mecanismos más costosos que los existentes para paginación.
• Al permitir que los segmentos varíen de tamaño, puede ser necesarios planes de reubicación a nivel de los discos, si los segmentos son devueltos a dicho dispositivo; lo que conlleva a nuevos costos.
• No se puede garantizar, que al salir un segmento de la memoria, este pueda ser traído fácilmente de nuevo, ya que será necesario encontrar nuevamente un área de memoria libre ajustada a su tamaño.
• La comparticion de segmentos permite ahorrar memoria, pero requiere de mecanismos adicionales da hardware y software.
Estas desventajas tratan de ser minimizadas, bajo la técnica conocida como Segmentación paginada.
7. Segmentación Paginada
Paginación y segmentación son técnicas diferentes, cada una de las cuales busca brindar las ventajas enunciadas anteriormente.
Para la segmentación se necesita que estén cargadas en memoria, áreas de tamaños variables. Si se requiere cargar un segmento en memoria; que antes estuvo en ella y fue removido a memoria secundaria; se necesita encontrar una región de la memoria lo suficientemente grande para contenerlo, lo cual no es siempre factible; en cambio "recargar" una pagina implica solo encontrar un merco de pagina disponible.
A nivel de paginación, si quiere referenciar en forma cíclicas n paginas, estas deberán ser cargadas una a una generándose varias interrupciones por fallas de paginas; bajo segmentación, esta pagina podría conformar un solo segmento, ocurriendo una sola interrupción, por falla de segmento. No obstante, si bajo segmentación, se desea acceder un área muy pequeña dentro de un segmento muy grande, este deberá cargarse completamente en memoria, desperdiciándose memoria; bajo paginación solo se cargara la página que contiene los ítems referenciados.
Puede hacerse una combinación de segmentación y paginación para obtener las ventajas de ambas. En lugar de tratar un segmento como una unidad contigua, este puede dividirse en páginas. Cada segmento puede ser descrito por su propia tabla de páginas.
Los segmentos son usualmente múltiplos de páginas en tamaño, y no es necesario que todas las páginas se encuentren en memoria principal a la vez; además las páginas de un mismo segmento, aunque se encuentren contiguas en memoria virtual; no necesitan estarlo en memoria real.
Las direcciones tienen tres componentes: (s, p,d), donde la primera indica el numero del segmento, la segunda el numero de la pagina dentro del segmento y la tercera el desplazamiento dentro de la pagina. Se deberán usar varias tablas:
• SMT (tabla de mapas de segmentos): una para cada proceso. En cada entrada de la SMT se almacena la información descrita bajo segmentación pura, pero en el campo de dirección se indicara la dirección de la PMT (tabla de mapas de páginas) que describe a las diferentes páginas de cada segmento.
• PMT (tabla de mapas de páginas): una por segmento; cada entrada de la PMT describe una página de un segmento; en la forma que se presento la pagina pura.
• TBM (tabla de bloques de memoria): para controlar asignación de páginas por parte del sistema operativo.
• JT (tabla de Jobs): que contiene las direcciones de comienzo de cada una de las SMT de los procesos que se ejecutan en memoria.
En el caso, de que un segmento sea de tamaño inferior o igual al de una pagina, no se necesita tener la correspondiente PMT, actuándose en igual forma que bajo segmentación pura; puede arreglarse un bit adicional (S) a cada entrada de la SMT, que indicara si el segmento esta paginado o no.
Ventajas de la segmentación paginada
El esquema de segmentación paginada tiene todas las ventajas de la segmentación y la paginación:
• Debido a que los espacios de memorias son segmentados, se garantiza la facilidad de implantar la comparticion y enlace.
• Como los espacios de memoria son paginados, se simplifican las estrategias de almacenamiento.
• Se elimina el problema de la fragmentación externa y la necesidad de compactación.
Desventajas de la segmentación paginada
• Las tres componentes de la dirección y el proceso de formación de direcciones hace que se incremente el costo de su implantación. El costo es mayor que en el caso de de segmentación pura o paginación pura.
• Se hace necesario mantener un número mayor de tablas en memoria, lo que implica un mayor costo de almacenamiento.
Sigue existiendo el problema de fragmentación interna de todas- o casi- todas las páginas finales de cada uno de los segmentos. Bajo paginación pura se desperdician solo la última página asignada, mientras que bajo segmentación – paginada el desperdicio puede ocurrir en todos los segmentos asignados.
8. Conclusiones
Para concluir se entiende que:
• En la memoria principal son ejecutados los programas y procesos de una computadora y es el espacio real que existe en memoria para que se ejecuten los procesos.
• La memoria virtual es aquella que le ofrece a las aplicaciones la ilusión de que están solas en el sistema y que pueden usar el espacio de direcciones completo.
• Las direcciones de memoria son de tres tipo: físicas, lógicas y lineales.
• El objetivo del intercambio es dar cabida a la ejecución de mas aplicaciones de las que pueden residir simultáneamente en la memoria del sistema.
• Las asignación consiste en determinar cual espacio vacío en la memoria principal es el mas indicado para ser asignado a un proceso.
• Las estrategias mas comunes para asignar espacios vacíos (huecos) son: primer ajuste, mejor ajuste, peor ajuste.
• La fragmentación es la memoria que queda desperdiciada al usar los métodos de gestión de memoria tal como la asignación.
• La fragmentación puede ser interna o externa.
• La paginación es una técnica de gestión de memoria en la cual el espacio de memoria se divide en secciones físicas de igual tamaño llamadas marcos de pagina, las cuales sirven como unidad de almacenamiento de información.
• La segmentación es un esquema de manejo de memoria mediante el cual la estructura del programa refleja su división lógica; llevándose a cabo una agrupación lógica de la información en bloques de tamaño variable denominados segmentos.
4.1.2 ADMINISTRADOR DE LA MEMORIA
El Administrador De Memoria se refiere a los distintos métodos y operaciones que se encargan de obtener la máxima utilidad de la memoria, organizando los procesos y programas que se ejecutan de manera tal que se aproveche de la mejor manera posible el espacio disponible.
Para poder lograrlo, la operación principal que realiza es la de trasladar la información que deberá ser ejecutada por el procesador, a la memoria principal. Actualmente esta administración se conoce como Memoria Virtual ya que no es la memoria física del procesador sino una memoria virtual que la representa. Entre algunas ventajas, esta memoria permite que el sistema cuente con una memoria más extensa teniendo la misma memoria real, con lo que esta se puede utilizar de manera más eficiente. Y por supuesto, que los programas que son utilizados no ocupen lugar innecesario.
Las técnicas que existen para la carga de programas en la memoria son: partición fija, que es la división de la memoria libre en varias partes (de igual o distinto tamaño) y la partición dinámica, que son las particiones de la memoria en tamaños que pueden ser variables, según la cantidad de memoria que necesita cada proceso.
Entre las principales operaciones que desarrolla la administración de memoria se encuentran la reubicación, que consiste en trasladar procesos activos dentro y fuera e la memoria principal para maximizar la utilización del procesador; la protección, mecanismos que protegen los procesos que se ejecutan de interferencias de otros procesos; uso compartido de códigos y datos, con lo que el mecanismo de protección permite que ciertos procesos de un mismo programa que comparten una tarea tengan memoria en común
Para poder lograrlo, la operación principal que realiza es la de trasladar la información que deberá ser ejecutada por el procesador, a la memoria principal. Actualmente esta administración se conoce como Memoria Virtual ya que no es la memoria física del procesador sino una memoria virtual que la representa. Entre algunas ventajas, esta memoria permite que el sistema cuente con una memoria más extensa teniendo la misma memoria real, con lo que esta se puede utilizar de manera más eficiente. Y por supuesto, que los programas que son utilizados no ocupen lugar innecesario.
Las técnicas que existen para la carga de programas en la memoria son: partición fija, que es la división de la memoria libre en varias partes (de igual o distinto tamaño) y la partición dinámica, que son las particiones de la memoria en tamaños que pueden ser variables, según la cantidad de memoria que necesita cada proceso.
Entre las principales operaciones que desarrolla la administración de memoria se encuentran la reubicación, que consiste en trasladar procesos activos dentro y fuera e la memoria principal para maximizar la utilización del procesador; la protección, mecanismos que protegen los procesos que se ejecutan de interferencias de otros procesos; uso compartido de códigos y datos, con lo que el mecanismo de protección permite que ciertos procesos de un mismo programa que comparten una tarea tengan memoria en común
4.1.3 JERARQUIA DE LA MEMORIA
Se conoce como jerarquía de memoria a la organización piramidal de la memoria en niveles, que tienen los ordenadores. Su objetivo es conseguir el rendimiento de una memoria de gran velocidad al coste de una memoria de baja velocidad, basándose en el principio de cercanía de referencias.
Los puntos básicos relacionados con la memoria pueden resumirse en:
• Cantidad
• Velocidad
• Coste
La cuestión de la cantidad es simple, cuanto más memoria haya disponible, más podrá utilizarse. La velocidad óptima para la memoria es la velocidad a la que el procesador puede trabajar, de modo que no haya tiempos de espera entre cálculo y cálculo, utilizados para traer operandos o guardar resultados. En suma, el costo de la memoria no debe ser excesivo, para que sea factible construir un equipo accesible.
Como puede esperarse los tres factores compiten entre sí, por lo que hay que encontrar un equilibrio. Las siguientes afirmaciones son válidas:
• A menor tiempo de acceso mayor coste
• A mayor capacidad mayor coste
• A mayor capacidad menor velocidad.
Se busca entonces contar con capacidad suficiente de memoria, con una velocidad que sirva para satisfacer la demanda de rendimiento y con un coste que no sea excesivo. Gracias a un principio llamado cercanía de referencias, es factible utilizar una mezcla de los distintos tipos y lograr un rendimiento cercano al de la memoria más rápida.
Los niveles que componen la jerarquía de memoria habitualmente son:
• Nivel 0: Registros
• Nivel 1: Memoria caché
• Nivel 2: Memoria principal
• Nivel 3: Disco duro (con el mecanismo de memoria virtual)
• Nivel 4: Redes(Actualmente se considera un nivel más de la jerarquía de memorias)

Los puntos básicos relacionados con la memoria pueden resumirse en:
• Cantidad
• Velocidad
• Coste
La cuestión de la cantidad es simple, cuanto más memoria haya disponible, más podrá utilizarse. La velocidad óptima para la memoria es la velocidad a la que el procesador puede trabajar, de modo que no haya tiempos de espera entre cálculo y cálculo, utilizados para traer operandos o guardar resultados. En suma, el costo de la memoria no debe ser excesivo, para que sea factible construir un equipo accesible.
Como puede esperarse los tres factores compiten entre sí, por lo que hay que encontrar un equilibrio. Las siguientes afirmaciones son válidas:
• A menor tiempo de acceso mayor coste
• A mayor capacidad mayor coste
• A mayor capacidad menor velocidad.
Se busca entonces contar con capacidad suficiente de memoria, con una velocidad que sirva para satisfacer la demanda de rendimiento y con un coste que no sea excesivo. Gracias a un principio llamado cercanía de referencias, es factible utilizar una mezcla de los distintos tipos y lograr un rendimiento cercano al de la memoria más rápida.
Los niveles que componen la jerarquía de memoria habitualmente son:
• Nivel 0: Registros
• Nivel 1: Memoria caché
• Nivel 2: Memoria principal
• Nivel 3: Disco duro (con el mecanismo de memoria virtual)
• Nivel 4: Redes(Actualmente se considera un nivel más de la jerarquía de memorias)

4.1.4 ESTRATEGIAS PARA ADMINISTRACION DE MEMORIA

Están dirigidas a la obtención del mejor uso posible del recurso del almacenamiento principal.
Se dividen en las siguientes categorías:
• Estrategias de búsqueda:
o Estrategias de búsqueda por demanda.
o Estrategias de búsqueda anticipada.
• Estrategias de colocación.
• Estrategias de reposición.
Las “estrategias de búsqueda” están relacionadas con el hecho de cuándo obtener el siguiente fragmento de programa o de datos para su inserción en la memoria principal.
En la “búsqueda por demanda” el siguiente fragmento de programa o de datos se carga al almacenamiento principal cuando algún programa en ejecución lo referencia.
Se considera que la “búsqueda anticipada” puede producir un mejor rendimiento del sistema.
Las “estrategias de colocación” están relacionadas con la determinación del lugar de la memoria donde se colocará (cargará) un programa nuevo.
Las “estrategias de reposición” están relacionadas con la determinación de qué fragmento de programa o de datos desplazar para dar lugar a los programas nuevos.
4.1.5 MULTIPROGRAMACION CON PARTICIONES FIJAS
• Cuando ocurre una petición de e / s la CPU normalmente no puede continuar el proceso hasta que concluya la operación de e / s requerida.
• Los periféricos de e / s frenan la ejecución de los procesos ya que comparativamente la CPU es varios órdenes de magnitud más rápida que los dispositiv os de e / s.
Los sistemas de “multiprogramación” permiten que varios procesos usuarios compitan al mismo tiempo por los recursos del sistema:
• Un trabajo en espera de e / s cederá la cpu a otro trabajo que esté listo para efectuar cómputos.
• Existe paralelismo entre el procesamiento y la e / s.
• Se incrementa la utilización de la cpu y la capacidad global de ejecución del sistema.
• Es necesario que varios trabajos residan a la vez en la memoria principal
• Los periféricos de e / s frenan la ejecución de los procesos ya que comparativamente la CPU es varios órdenes de magnitud más rápida que los dispositiv os de e / s.
Los sistemas de “multiprogramación” permiten que varios procesos usuarios compitan al mismo tiempo por los recursos del sistema:
• Un trabajo en espera de e / s cederá la cpu a otro trabajo que esté listo para efectuar cómputos.
• Existe paralelismo entre el procesamiento y la e / s.
• Se incrementa la utilización de la cpu y la capacidad global de ejecución del sistema.
• Es necesario que varios trabajos residan a la vez en la memoria principal
4.1.5 MULTIPROGRAMACION DE PARTICION VARIABLE

Los procesos ocupan tanto espacio como necesitan, pero obviamente no deben superar el espacio disponible de memoria .
No hay límites fijos de memoria, es decir que la partición de un trabajo es su propio tamaño.
Se consideran “esquemas de asignación contigua”, dado que un programa debe ocupar posiciones adyacentes de almacenamiento.
Los procesos que terminan dejan disponibles espacios de memoria principal llamados “agujeros”:
• Pueden ser usados por otros trabajos que cuando finalizan dejan otros “agujeros” menores.
• En sucesivos pasos los “agujeros” son cada vez más numerosos pero más pequeños, por lo que se genera un desperdicio de memoria principal.
Combinación de agujeros (áreas libres)
Consiste en fusionar agujeros adyacentes para formar uno sencillo más grande.
Se puede hacer cuando un trabajo termina y el almacenamiento que libera tiene límites con otros agujeros.
4.2 MEMORIA REAL
La memoria real o principal es en donde son ejecutados los programas y procesos de una computadora y es el espacio real que existe en memoria para que se ejecuten los procesos. Por lo general esta memoria es de mayor costo que la memoria secundaria, pero el acceso a la información contenida en ella es de más rápido acceso. Solo la memoria cache es más rápida que la principal, pero su costo es a su vez mayor.
4.2.1 ADMINISTRACION DE LA MEMORIA CON MAPAS DE BITS
Podemos dividir la memoria en pequeñas unidades, y registrar en un mapa de bits las unidades ocupadas y desocupadas. Las unidades pueden ser de unas pocas palabras cada una, hasta de un par de KB. A mayor tamaño de las unidades, menor espacio ocupa el mapa de bits, pero puede haber mayor fragmentación interna. Desventaja: para encontrar hoyo de n unidades hay que recorrer el mapa hasta encontrar n ceros seguidos (puede ser caro).
4.2.2 Administración de la memoria con listas enlazadas

Mantiene una lista enlazada de segmentos de memoria asignados y libres, donde un segmento es un proceso o un hueco entre dos procesos.
•Si la lista se ordena por dirección es más fácil su actualización.
•Si hay dos listas, una para memoria usada y otra para huecos, la asignación es más rápida, pero la liberación es más lenta
•Ocurre lo mismo para asignar hueco de intercambio.
4.2.3DISTRIBUCION DEL ESPACIO PARA INTERCAMBIO.
En algunos sistemas, cuando un proceso esta en la memoria, no se le puede asignar espacio en disco. Cuando deba intercambiarse, puede colocarse en alguna otra parte del disco.los algoritmos para administrar el espacio de intercambio son los mismos que se emplean para administrar la memoria principal.
En otros sistemas, cuando se crea un proceso, el espacio para intercambio se asigna para el en disco. Cada ves que el proceso se intercambia, siempre se cambia a su espacio asignado, en lugar de dirigirse a un lugar diferente en cada ocasión. Cuando el proceso sale, se desasigna el espacio para el intercambio.
La única diferencia es que el espacio en el disco para un proceso debe asignarse como un numero integral de bloques de disco.por lo tanto, un proceso de tamaño 13.5 k que utiliza un disco con bloques de 1k se redondeara a 14k antes de que se busquen las estructuras de datos del espacio en el disco
En otros sistemas, cuando se crea un proceso, el espacio para intercambio se asigna para el en disco. Cada ves que el proceso se intercambia, siempre se cambia a su espacio asignado, en lugar de dirigirse a un lugar diferente en cada ocasión. Cuando el proceso sale, se desasigna el espacio para el intercambio.
La única diferencia es que el espacio en el disco para un proceso debe asignarse como un numero integral de bloques de disco.por lo tanto, un proceso de tamaño 13.5 k que utiliza un disco con bloques de 1k se redondeara a 14k antes de que se busquen las estructuras de datos del espacio en el disco
4.3 Memoria virtual
Cómo la memoria virtual se mapea a la memoria física La Memoria virtual es un concepto que permite al software usar más memoria principal que la que realmente posee el ordenador. La mayoría de los ordenadores tienen cuatro tipos de memoria: registros en la CPU, la memoria cache (tanto dentro como fuera del CPU), la memoria física (generalmente en forma de RAM, donde la CPU puede escribir y leer directa y razonablemente rápido) y el disco duro que es mucho más lento, pero también más grande y barato.
Muchas aplicaciones requieren el acceso a más información (código y datos) que la que se puede mantener en memoria física. Esto es así sobre todo cuando el sistema operativo permite múltiples procesos y aplicaciones ejecutándose simultáneamente. Una solución al problema de necesitar mayor cantidad de memoria de la que se posee consiste en que las aplicaciones mantengan parte de su información en disco, moviéndola a la memoria principal cuando sea necesario. Hay varias formas de hacer esto. Una opción es que la aplicación misma sea responsable de decidir qué información será guardada en cada sitio (segmentación), y de traerla y llevarla. La desventaja de esto, además de la dificultad en el diseño e implementación del programa, es que es muy probable que los intereses sobre la memoria de dos o varios programas generen conflictos entre sí: cada programador podría realizar su diseño teniendo en cuenta que es el único programa ejecutándose en el sistema.
 La alternativa es usar memoria virtual, donde la combinación entre hardware especial y el sistema operativo hace uso de la memoria principal y la secundaria para hacer parecer que el ordenador tiene mucha más memoria principal (RAM) que la que realmente posee. Este método es invisible a los procesos. La cantidad de memoria máxima que se puede hacer ver que hay tiene que ver con las características del procesador. Por ejemplo, en un sistema de 32 bits, el máximo es 232, lo que da aproximadamente 4000 Megabytes (4 Gigabytes). Todo esto hace el trabajo del programador de aplicaciones mucho más fácil, al poder ignorar completamente la necesidad de mover datos entre los distintos espacios de memoria.
La alternativa es usar memoria virtual, donde la combinación entre hardware especial y el sistema operativo hace uso de la memoria principal y la secundaria para hacer parecer que el ordenador tiene mucha más memoria principal (RAM) que la que realmente posee. Este método es invisible a los procesos. La cantidad de memoria máxima que se puede hacer ver que hay tiene que ver con las características del procesador. Por ejemplo, en un sistema de 32 bits, el máximo es 232, lo que da aproximadamente 4000 Megabytes (4 Gigabytes). Todo esto hace el trabajo del programador de aplicaciones mucho más fácil, al poder ignorar completamente la necesidad de mover datos entre los distintos espacios de memoria.
Aunque la memoria virtual podría estar implementada por el software del sistema operativo, en la práctica casi siempre se usa una combinación de hardware y software, dado el esfuerzo extra que implicaría para el procesador.
Operación básica [editar]Cuando se usa Memoria Virtual, o cuando una dirección es leída o escrita por la CPU, una parte del hardware dentro de la computadora traduce las direcciones de memoria generadas por el software (direcciones virtuales) en:
la dirección real de memoria (la dirección de memoria física), o una indicación de que la dirección de memoria deseada no se encuentra en memoria principal (llamado excepción de memoria virtual)
En el primer caso, la referencia a la memoria es completada, como si la memoria virtual no hubiera estado involucrada: el software accede donde debía y sigue ejecutando normalmente. En el segundo caso, el sistema operativo es invocado para manejar la situación y permitir que el programa siga ejecutando o aborte según sea el caso. La memoria virtual es una técnica para proporcionar la simulación de un espacio de memoria mucho mayor que la memoria física de una máquina. Esta “ilusión” permite que los programas se ejecuten sin tener en cuenta el tamaño exacto de la memoria física.
La ilusión de la memoria virtual está soportada por el mecanismo de traducción de memoria, junto con una gran cantidad de almacenamiento rápido en disco duro. Así en cualquier momento el espacio de direcciones virtual hace un seguimiento de tal forma que una pequeña parte de él, está en memoria real y el resto almacenado en el disco, y puede ser referenciado fácilmente.
Debido a que sólo la parte de memoria virtual que está almacenada en la memoria principal, es accesible a la CPU, según un programa va ejecutándose, la proximidad de referencias a memoria cambia, necesitando que algunas partes de la memoria virtual se traigan a la memoria principal desde el disco, mientras que otras ya ejecutadas, se pueden volver a depositar en el disco (archivos de paginación).
La memoria virtual ha llegado a ser un componente esencial de la mayoría de los sistemas operativos actuales. Y como en un instante dado, en la memoria sólo se tienen unos pocos fragmentos de un proceso dado, se pueden mantener más procesos en la memoria. Es más, se ahorra tiempo, porque los fragmentos que no se usan no se cargan ni se descargan de la memoria. Sin embargo, el sistema operativo debe saber cómo gestionar este esquema.
La memoria virtual también simplifica la carga del programa para su ejecución llamada reubicación, este procedimiento permite que el mismo programa se ejecute en cualquier posición de la memoria física.
En un estado estable, prácticamente toda la memoria principal estará ocupada con fragmentos de procesos, por lo que el procesador y el S.O tendrán acceso directo a la mayor cantidad de procesos posibles, y cuando el S.O traiga a la memoria un fragmento, deberá expulsar otro. Si expulsa un fragmento justo antes de ser usado, tendrá que traer de nuevo el fragmento de manera casi inmediata. Demasiados intercambios de fragmentos conducen a lo que se conoce como hiperpaginación: donde el procesador consume más tiempo intercambiando fragmentos que ejecutando instrucciones de usuario. Para evitarlo el sistema operativo intenta adivinar, en función de la historia reciente, qué fragmentos se usarán con menor probabilidad en un futuro próximo (véase algoritmos de reemplazo de páginas).
Los argumentos anteriores se basan en el principio de cercanía de referencias o principio de localidad que afirma que las referencias a los datos y el programa dentro de un proceso tienden a agruparse. Por lo tanto, es válida la suposición de que, durante cortos períodos de tiempo, se necesitarán sólo unos pocos fragmentos de un proceso.
Una manera de confirmar el principio de cercanía es considerar el rendimiento de un proceso en un entorno de memoria virtual.
El principio de cercanía sugiere que los esquemas de memoria virtual pueden funcionar. Para que la memoria virtual sea práctica y efectiva, se necesitan dos ingredientes. Primero, tiene que existir un soporte de hardware y, en segundo lugar, el S.O debe incluir un software para gestionar el movimiento de páginas o segmentos entre memoria secundaria y memoria principal.
Justo después de obtener la dirección física y antes de consultar el dato en memoria principal se busca en memoria-cache, si esta entre los datos recientemente usados la búsqueda tendrá éxito, pero si falla, la memoria virtual consulta memoria principal , ó, en el peor de los casos se consulta de disco (swapping).
Detalles [editar]La traducción de las direcciones virtuales a reales es implementada por una Unidad de Manejo de Memoria (MMU). El sistema operativo es el responsable de decidir qué partes de la memoria del programa es mantenida en memoria física. Además mantiene las tablas de traducción de direcciones (si se usa paginación la tabla se denomina tabla de paginación), que proveen las relaciones entre direcciones virtuales y físicas, para uso de la MMU. Finalmente, cuando una excepción de memoria virtual ocurre, el sistema operativo es responsable de ubicar un área de memoria física para guardar la información faltante, trayendo la información desde el disco, actualizando las tablas de traducción y finalmente continuando la ejecución del programa que dio la excepción de memoria virtual desde la instrucción que causó el fallo.
En la mayoría de las computadoras, las tablas de traducción de direcciones de memoria se encuentran en memoria física. Esto implica que una referencia a una dirección virtual de memoria necesitará una o dos referencias para encontrar la entrada en la tabla de traducción, y una más para completar el acceso a esa dirección.
Para acelerar el desempeño de este sistema, la mayoría de las Unidades Centrales de Proceso (CPU) incluyen una MMU en el mismo chip, y mantienen una tabla de las traducciones de direcciones virtuales a reales usadas recientemente, llamada Translation Lookaside Buffer (TLB). El uso de este buffer hace que no se requieran referencias de memoria adicionales, por lo que se ahorra tiempo al traducir.
En algunos procesadores, esto es realizado enteramente por el hardware. En otros, se necesita de la asistencia del sistema operativo: se levanta una excepción, y en ella el sistema operativo reemplaza una de las entradas del TLB con una entrada de la tabla de traducción, y la instrucción que hizo la referencia original a memoria es reejecutada.
El hardware que tiene soporte para memoria virtual, la mayoría de la veces también permite protección de memoria. La MMU puede tener la habilidad de variar su forma de operación de acuerdo al tipo de referencia a memoria (para leer, escribir, o ejecutar), así como el modo en que se encontraba el CPU en el momento de hacer la referencia a memoria. Esto permite al sistema operativo proteger su propio código y datos (como las tablas de traducción usadas para memoria virtual) de corromperse por una aplicación, y de proteger a las aplicaciones que podrían causar problemas entre sí.
Paginación y memoria virtual [editar]La memoria virtual usualmente (pero no necesariamente) es implementada usando paginación. En paginación, los bits menos significativos de la dirección de memoria virtual son preservados y usados directamente como los bits de orden menos significativos de la dirección de memoria física. Los bits más significativos son usados como una clave en una o más tablas de traducción de direcciones (llamadas tablas de paginación, para encontrar la parte restante de la dirección física buscada.
Muchas aplicaciones requieren el acceso a más información (código y datos) que la que se puede mantener en memoria física. Esto es así sobre todo cuando el sistema operativo permite múltiples procesos y aplicaciones ejecutándose simultáneamente. Una solución al problema de necesitar mayor cantidad de memoria de la que se posee consiste en que las aplicaciones mantengan parte de su información en disco, moviéndola a la memoria principal cuando sea necesario. Hay varias formas de hacer esto. Una opción es que la aplicación misma sea responsable de decidir qué información será guardada en cada sitio (segmentación), y de traerla y llevarla. La desventaja de esto, además de la dificultad en el diseño e implementación del programa, es que es muy probable que los intereses sobre la memoria de dos o varios programas generen conflictos entre sí: cada programador podría realizar su diseño teniendo en cuenta que es el único programa ejecutándose en el sistema.
 La alternativa es usar memoria virtual, donde la combinación entre hardware especial y el sistema operativo hace uso de la memoria principal y la secundaria para hacer parecer que el ordenador tiene mucha más memoria principal (RAM) que la que realmente posee. Este método es invisible a los procesos. La cantidad de memoria máxima que se puede hacer ver que hay tiene que ver con las características del procesador. Por ejemplo, en un sistema de 32 bits, el máximo es 232, lo que da aproximadamente 4000 Megabytes (4 Gigabytes). Todo esto hace el trabajo del programador de aplicaciones mucho más fácil, al poder ignorar completamente la necesidad de mover datos entre los distintos espacios de memoria.
La alternativa es usar memoria virtual, donde la combinación entre hardware especial y el sistema operativo hace uso de la memoria principal y la secundaria para hacer parecer que el ordenador tiene mucha más memoria principal (RAM) que la que realmente posee. Este método es invisible a los procesos. La cantidad de memoria máxima que se puede hacer ver que hay tiene que ver con las características del procesador. Por ejemplo, en un sistema de 32 bits, el máximo es 232, lo que da aproximadamente 4000 Megabytes (4 Gigabytes). Todo esto hace el trabajo del programador de aplicaciones mucho más fácil, al poder ignorar completamente la necesidad de mover datos entre los distintos espacios de memoria. Aunque la memoria virtual podría estar implementada por el software del sistema operativo, en la práctica casi siempre se usa una combinación de hardware y software, dado el esfuerzo extra que implicaría para el procesador.
Operación básica [editar]Cuando se usa Memoria Virtual, o cuando una dirección es leída o escrita por la CPU, una parte del hardware dentro de la computadora traduce las direcciones de memoria generadas por el software (direcciones virtuales) en:
la dirección real de memoria (la dirección de memoria física), o una indicación de que la dirección de memoria deseada no se encuentra en memoria principal (llamado excepción de memoria virtual)
En el primer caso, la referencia a la memoria es completada, como si la memoria virtual no hubiera estado involucrada: el software accede donde debía y sigue ejecutando normalmente. En el segundo caso, el sistema operativo es invocado para manejar la situación y permitir que el programa siga ejecutando o aborte según sea el caso. La memoria virtual es una técnica para proporcionar la simulación de un espacio de memoria mucho mayor que la memoria física de una máquina. Esta “ilusión” permite que los programas se ejecuten sin tener en cuenta el tamaño exacto de la memoria física.
La ilusión de la memoria virtual está soportada por el mecanismo de traducción de memoria, junto con una gran cantidad de almacenamiento rápido en disco duro. Así en cualquier momento el espacio de direcciones virtual hace un seguimiento de tal forma que una pequeña parte de él, está en memoria real y el resto almacenado en el disco, y puede ser referenciado fácilmente.
Debido a que sólo la parte de memoria virtual que está almacenada en la memoria principal, es accesible a la CPU, según un programa va ejecutándose, la proximidad de referencias a memoria cambia, necesitando que algunas partes de la memoria virtual se traigan a la memoria principal desde el disco, mientras que otras ya ejecutadas, se pueden volver a depositar en el disco (archivos de paginación).
La memoria virtual ha llegado a ser un componente esencial de la mayoría de los sistemas operativos actuales. Y como en un instante dado, en la memoria sólo se tienen unos pocos fragmentos de un proceso dado, se pueden mantener más procesos en la memoria. Es más, se ahorra tiempo, porque los fragmentos que no se usan no se cargan ni se descargan de la memoria. Sin embargo, el sistema operativo debe saber cómo gestionar este esquema.
La memoria virtual también simplifica la carga del programa para su ejecución llamada reubicación, este procedimiento permite que el mismo programa se ejecute en cualquier posición de la memoria física.
En un estado estable, prácticamente toda la memoria principal estará ocupada con fragmentos de procesos, por lo que el procesador y el S.O tendrán acceso directo a la mayor cantidad de procesos posibles, y cuando el S.O traiga a la memoria un fragmento, deberá expulsar otro. Si expulsa un fragmento justo antes de ser usado, tendrá que traer de nuevo el fragmento de manera casi inmediata. Demasiados intercambios de fragmentos conducen a lo que se conoce como hiperpaginación: donde el procesador consume más tiempo intercambiando fragmentos que ejecutando instrucciones de usuario. Para evitarlo el sistema operativo intenta adivinar, en función de la historia reciente, qué fragmentos se usarán con menor probabilidad en un futuro próximo (véase algoritmos de reemplazo de páginas).
Los argumentos anteriores se basan en el principio de cercanía de referencias o principio de localidad que afirma que las referencias a los datos y el programa dentro de un proceso tienden a agruparse. Por lo tanto, es válida la suposición de que, durante cortos períodos de tiempo, se necesitarán sólo unos pocos fragmentos de un proceso.
Una manera de confirmar el principio de cercanía es considerar el rendimiento de un proceso en un entorno de memoria virtual.
El principio de cercanía sugiere que los esquemas de memoria virtual pueden funcionar. Para que la memoria virtual sea práctica y efectiva, se necesitan dos ingredientes. Primero, tiene que existir un soporte de hardware y, en segundo lugar, el S.O debe incluir un software para gestionar el movimiento de páginas o segmentos entre memoria secundaria y memoria principal.
Justo después de obtener la dirección física y antes de consultar el dato en memoria principal se busca en memoria-cache, si esta entre los datos recientemente usados la búsqueda tendrá éxito, pero si falla, la memoria virtual consulta memoria principal , ó, en el peor de los casos se consulta de disco (swapping).
Detalles [editar]La traducción de las direcciones virtuales a reales es implementada por una Unidad de Manejo de Memoria (MMU). El sistema operativo es el responsable de decidir qué partes de la memoria del programa es mantenida en memoria física. Además mantiene las tablas de traducción de direcciones (si se usa paginación la tabla se denomina tabla de paginación), que proveen las relaciones entre direcciones virtuales y físicas, para uso de la MMU. Finalmente, cuando una excepción de memoria virtual ocurre, el sistema operativo es responsable de ubicar un área de memoria física para guardar la información faltante, trayendo la información desde el disco, actualizando las tablas de traducción y finalmente continuando la ejecución del programa que dio la excepción de memoria virtual desde la instrucción que causó el fallo.
En la mayoría de las computadoras, las tablas de traducción de direcciones de memoria se encuentran en memoria física. Esto implica que una referencia a una dirección virtual de memoria necesitará una o dos referencias para encontrar la entrada en la tabla de traducción, y una más para completar el acceso a esa dirección.
Para acelerar el desempeño de este sistema, la mayoría de las Unidades Centrales de Proceso (CPU) incluyen una MMU en el mismo chip, y mantienen una tabla de las traducciones de direcciones virtuales a reales usadas recientemente, llamada Translation Lookaside Buffer (TLB). El uso de este buffer hace que no se requieran referencias de memoria adicionales, por lo que se ahorra tiempo al traducir.
En algunos procesadores, esto es realizado enteramente por el hardware. En otros, se necesita de la asistencia del sistema operativo: se levanta una excepción, y en ella el sistema operativo reemplaza una de las entradas del TLB con una entrada de la tabla de traducción, y la instrucción que hizo la referencia original a memoria es reejecutada.
El hardware que tiene soporte para memoria virtual, la mayoría de la veces también permite protección de memoria. La MMU puede tener la habilidad de variar su forma de operación de acuerdo al tipo de referencia a memoria (para leer, escribir, o ejecutar), así como el modo en que se encontraba el CPU en el momento de hacer la referencia a memoria. Esto permite al sistema operativo proteger su propio código y datos (como las tablas de traducción usadas para memoria virtual) de corromperse por una aplicación, y de proteger a las aplicaciones que podrían causar problemas entre sí.
Paginación y memoria virtual [editar]La memoria virtual usualmente (pero no necesariamente) es implementada usando paginación. En paginación, los bits menos significativos de la dirección de memoria virtual son preservados y usados directamente como los bits de orden menos significativos de la dirección de memoria física. Los bits más significativos son usados como una clave en una o más tablas de traducción de direcciones (llamadas tablas de paginación, para encontrar la parte restante de la dirección física buscada.
Suscribirse a:
Entradas (Atom)